
Thesis
Increasingly, data is everywhere. In every device, every online interaction, every financial transaction. In 2006, British mathematician Clive Humby coined the phrase, “data is the new oil.” At that point the world was generating 161 billion gigabytes of data. In 2021, the number had grown 500x to 79 zettabytes, and is expected to continue growing to 150 zettabytes by 2025.
While data may be the new oil, we still need infrastructure to transport and use the oil. Extract, transform, and load (ETL) is the methodology for “combining data from multiple sources into a large, central repository.” While there are large established ETL platforms like Informatica PowerCenter and Talend Open Studio, some would joke that Microsoft Excel is the most common ETL tool in the world. People can use Excel to manipulate comma-separated value (CSV) files; a text-file format that uses “commas to separate values, and newlines to separate records.”
While data transfer methods, like APIs, have become increasingly common, the reality is that a large portion of data transfers still happen through CSVs. One former executive from a Fortune 500 company shared with Contrary Research that large companies will often be processing over 100 million CSV files per year, often spending tens of millions of dollars on CSV import to manage the data. However, the process of manually validating and cleaning that data can be time-intensive and error-prone.
That’s where OneSchema* comes in. OneSchema is an embeddable spreadsheet importer and validator that can automate the process of importing CSV files or excel workbooks with up to 20 million rows, while also validating the data to ensure that formatting is correct and the data is complete. According to the company, OneSchema can automate 90% of the workflow for mapping, transforming, and validating CSV import files.
Founding Story
OneSchema was founded by Christina Gilbert and Andrew Luo (CEO) in February 2021.
Prior to founding the company, Gilbert spent four years as a product manager at Google. Meanwhile, Luo had previously been an early software engineer at Affinity, an investor CRM product with large investors as customers, such as Mass Mutual, Swiss Re, Bain Capital Ventures, and others.
His experience building at Affinity required helping customers manage large amounts of data, often coming from other CRMs with a CSV file type. In a May 2024 interview with Contrary Research, Luo described the experience this way:
“At Affinity, when we built an importer we thought it would be simple. A CSV parser in front of a SQL database. But it turns out that every data type in the world, whether its a number, an address, a phone number, or anything, can have 20+ different variations. Explaining the difference between October 10th, 2023 and 10/10/23 requires explanations that have exponentially more code to explain why something is wrong. So handling edge cases requires months of engineering time.”
While Affinity expected the project to take two months, it ended up taking two years. A key part of that process was building an engine to understand data that wasn’t normalized. The process of effectively normalizing data for ingestion required a surprising amount of engineering resources. That complexity led Luo and Gilbert to build OneSchema to solve that problem. In particular, the focus would be on enabling non-technical users to manage the data transformation and ingestion process without requiring engineering resources.
Product
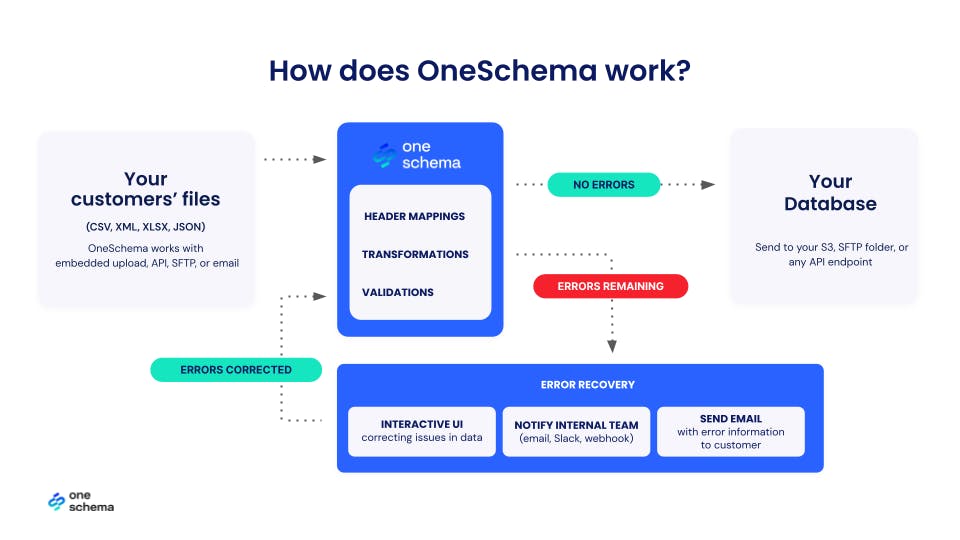
Source: OneSchema
OneSchema’s core value proposition is to manage the process of data exchange via CSV imports more easily. OneSchema CEO Andrew Luo, in May 2024 interview with Contrary Research, described the product surface area this way:
“As the standard for cross-company data exchange, there will be one-time uploads of CSVs as well as recurring uploads. For one-time uploads, OneSchema’s Embeddable Importer wraps a button inside your web application, and makes it possible to automatically clean spreadsheets that get uploaded. For companies that frequently receive CSVs through Secure File Transfer Protocol (SFTP), email, or API, that’s where FileFeeds comes in. Non-technical users can record a set of transformations and replay them on all subsequent spreadsheet integrations.”
Embeddable Importer
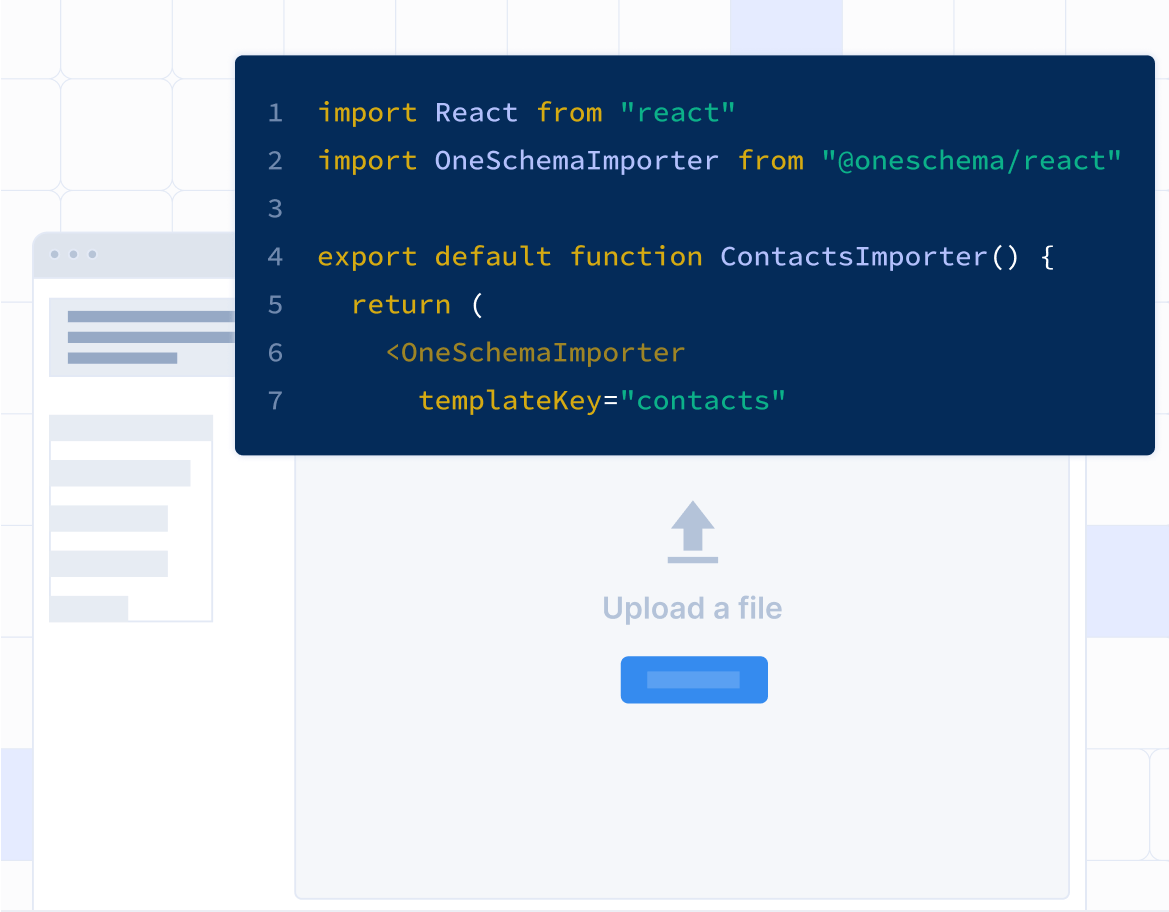
Source: OneSchema
For use cases that require one-off CSV uploads, this process typically requires a CSV to be imported and then processed. The process for validating the data in a CSV import manually can be time-intensive and error-prone. Products like self-serve CRMs, restaurant POS, and copywriting tools will require their customers to upload relevant CSVs. These could include data like contact information, menu SKUs, or outreach targets.
Traditionally, building an importer from scratch will fail to address a wide variety of edge cases like data formats, cleanliness, or missing data. This can lead to onboarding delays, customer churn, increased number of customer service tickets, and negative user experience.
OneSchema’s Embeddable Importer is a widget installed in a customer’s application that is connected to OneSchema’s data validation engine, and can more easily import CSVs while controlling for a wide variety of edge cases in the data ingestion process. As OneSchema describes it, validations are “pre-determined rule[s] to which data must conform” which determine how to clean data. The Importer can handle files up to 4 GB in one second and can manage spreadsheets with up to 20 million rows. The Importer also enables users to more quickly clean their data in bulk with tools like autofix, find-and-replace, and others.
Embeddable FileFeeds
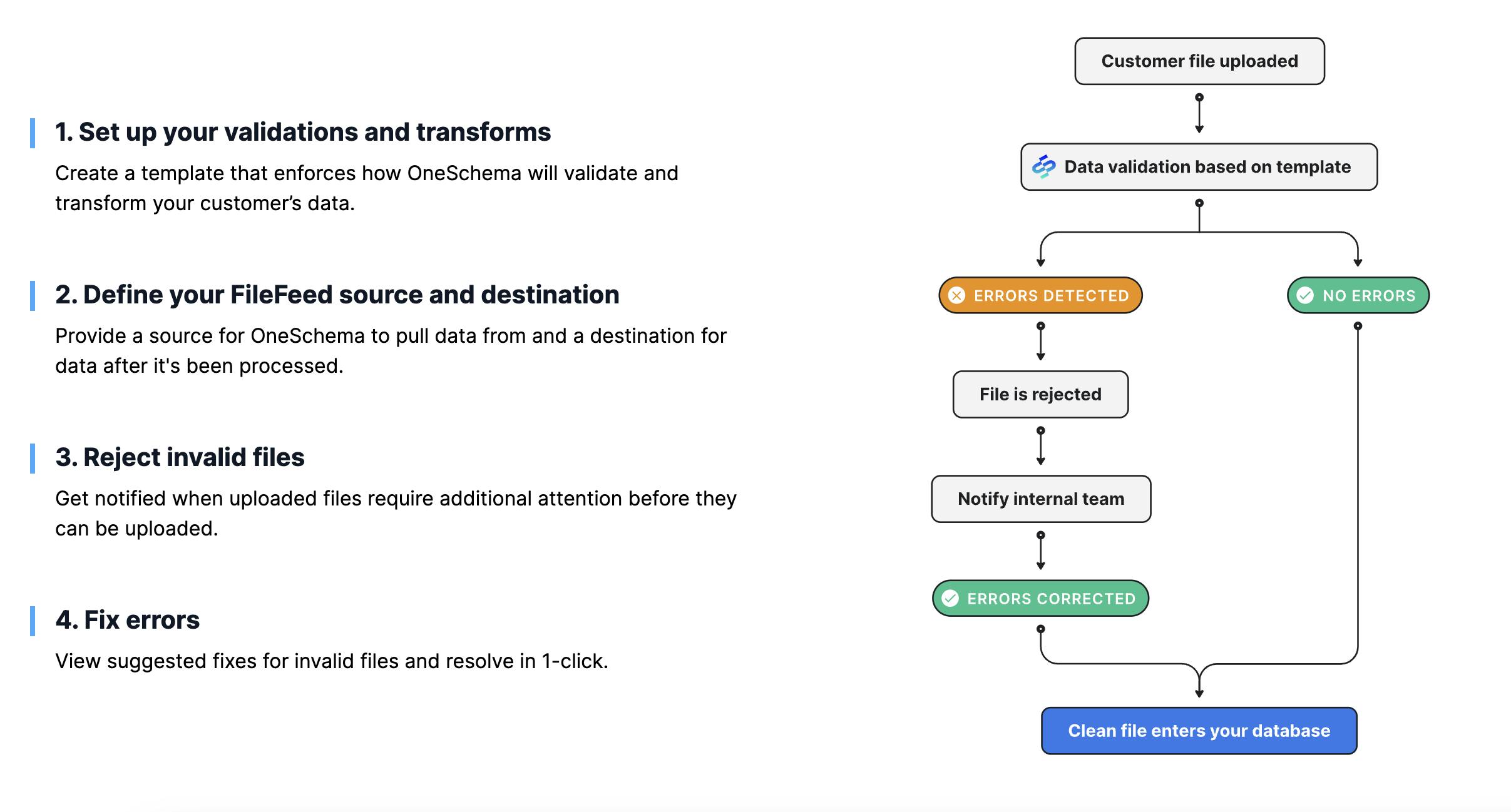
Source: OneSchema
In some use cases, data is frequently being transferred via CSV import to import data. For example, transaction files from an ERP, inventory files from a POS, or employee files from an HRIS. Often, this kind of data may need to be transferred weekly, or even daily. Often managing these data transfers requires engineering resources to write Python scripts. However, these scripts can be brittle, and can break either due to volume or complexity. Fixing that problem requires engineering resources each time.
OneSchema FileFeeds enables customers to build workflows for specific data flows dependent on customer need. OneSchema claims that its FileFeeds product can “automate 90% of the workflow for mapping, transforming, and validating CSV import files received through an API, SFTP server, or email server.” It can therefore automate csv mapping as well as validate CSV imports, helping clean data.
Customers can create data pipelines for workflows around specific customer needs. Users can use mappings around data needs, and record transformations around particular spreadsheets. One example may be working with retail data where the software needs 0, 1, and 2 as inputs, but the retailer uploads data with S, M, and L. The user can record that specific transformation, formatting the data into the required format to import data, and then replay that data across every upload that gets received.
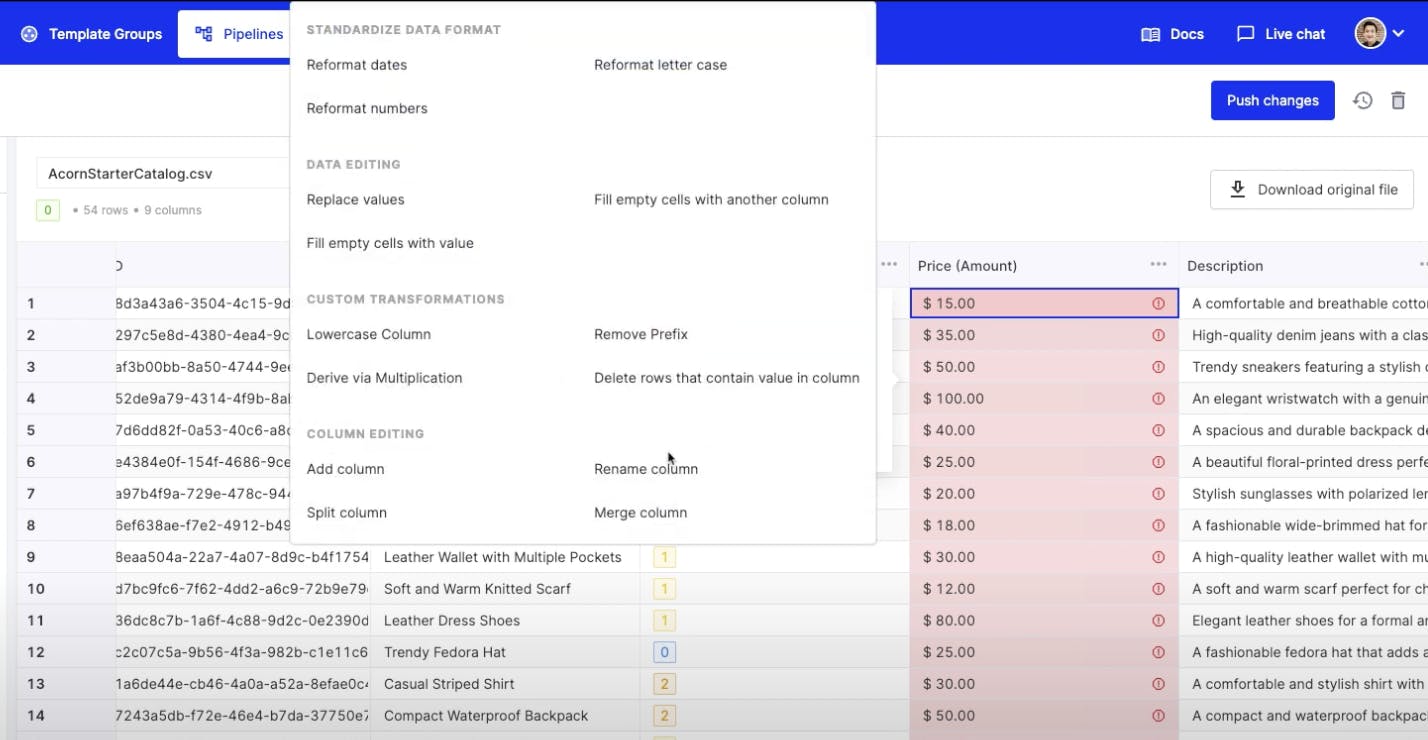
Source: OneSchema
In addition to bespoke confirmations, OneSchema also offers a library of standard data transformations like replacing values, adding and splitting columns, and standardizing data formats. OneSchema can also recommend specific transformations based on its estimation of the data issue and the most likely correction to resolve any issues.
Data Normalization Engine
As previously mentioned, one of the core issues with manually building a CSV importer is the lack of capability around edge cases. Each time a new issue arises in a custom-built CSV importer it will likely break the importer, and require engineering resources to fix. OneSchema addresses this limitation by building all of its data transformation products on the foundation of a data normalization engine. Andrew Luo, in a May 2024 interview with Contrary Research, described the product this way:
“The core of OneSchema is the data normalization engine. This is the set of validations and transformations that are built on the knowledge of every spreadsheet OneSchema has ever ingested. This is our unique differentiator given that its no-code; you don’t need engineers to write brittle Python scripts or one-off transformations in code. Someone on your team, even non-technical people, can configure this using a no-code UI without needing an engineer.”
Market
Customer

Source: OneSchema
OneSchema’s target customer is quite broad, including anyone that is moving data via CSV either semi-often or frequently. If “data is the new oil,” that includes almost everyone. In particular, there are two types of customers that feel the pain most poignantly. First, mid-market companies see these data transfers as taking up valuable engineering resources that could be deployed elsewhere. Second, large enterprises use CSV imports for a number of security or compliance reasons to keep data safe, as well as other functional issues such as version control or downstream data sharing limitations. However, these efforts often require large teams of data analysts to manage.
In a May 2024 interview with Contrary Research, OneSchema CEO Andrew Luo shared how OneSchema’s target customer has evolved:
“We started with SMB and mid-market up to 1K employees. Product managers use OneSchema to avoid years of cycles building importers. As we move into enterprises like large consulting firms or supply chain companies, what we see is that, rather than being owned by a product manager, these problems are owned by data analysts and professional services teams. They build brittle workflows that scale with headcount.”
As of January 2025, some of OneSchema’s customers include tech companies such as Toast, Vanta, Scale AI, Pave**,* Ramp*, Personio, and Airbase. In addition, several of OneSchema’s customers are larger enterprises, such as CreditSafe and Huron Consulting.
Market Size
The market for enterprise data management is estimated to grow from $77 billion in 2020 to $123 billion by 2025. Within OneSchema’s initial target of mid-market software companies there are ~100K potential customers in the US. More broadly, OneSchema has also been able to address use cases in management consulting, ecommerce, insurance, and financial services which broadens the number of potential customers to 3 million.
Competition
As a horizontal tool addressing both mid-market and enterprise customers, OneSchema has several subsets of competitors each with different focuses. When customers are considering CSV import alternatives, they typically compare OneSchema in relation to mid-market data migration tools, enterprise interoperability platforms, embedded iPaaS, and unified API platforms.
Mid-Market Competitors
Flatfile: Founded in 2018, Flatfile provides “AI-powered data migration.” The company has had similar product set to OneSchema with both an embeddable importer it calls Portal, and collaborative data import workflows, which Flatfile calls Projects. However, Flatfile is reportedly pushing customers to migrate to its new Platform product. This product focuses on a “build-with” strategy, and has become more akin to developer scaffolding now. OneSchema, on the other hand, is meant to be out of the box. Flatfile’s customers are typically mid-market, such as startups like ClickUp. Flatfile has raised nearly $100 million of funding from investors like Tiger Global, Scale Venture Partners, and Workday Ventures. When comparing OneSchema vs. FlatFile, OneSchema emphasizes its capabilities around setup time, customizations, and automated data fixes.
Dromo: Founded in 2019, Dromo is a “self-service data file importer.” The company offers two products, Dromo Embedded and Dromo Headless. Dromo Embedded competes with OneSchema’s Embeddable Importer and offers CSV imports alongside “AI-powered data validation.” Meanwhile, Dromo Headless is similar to OneSchema’s Embedded FileFeeds where users can build backend CSV import processes to “replace one-off custom scripts.” As of February 2025, the company had not announced any funding. When comparing OneSchema vs. Dromo, OneSchema emphasizes its capability around file sizes (e.g. managing 100K+ rows, bulk issue review, and customer service responsiveness and engagement. Meanwhile, Dromo emphasizes its price transparency at $399 per month for its Pro account, and developer experience around documentation.
Osmos: Founded in 2019, Osmos is a data ingestion engine reportedly used by customers like Netflix, Rakuten, and Harman. As of February 2025, the company had raised $18 million in funding from investors such as Lightspeed Ventures, CRV, and Pear VC. The company reportedly leverages GPT for auditable data transformations. When comparing OneSchema vs. Osmos, OneSchema emphasizes its focus on data compliance, no-code validations, extensive variety of SDKs, and a broad capability around responsive customer service.
CSVBox: CSVBox is a CSV import widget primarily focused on smaller startups. According to the company, it differs from OneSchema because it is less feature rich, and therefore less complex to use than OneSchema. As of February 2025, the company had not announced any funding.
Enterprise Competitors
Dell Boomi: Founded in 2000, Boomi is an enterprise data integration platform that was acquired by DELL in 2010 before subsequently being sold to private equity firms Francisco Partners and TPG in 2021. Boomi’s product provides an integration capability for enterprises to weave together different applications with workflows including data integration, API management, data quality, and workflow automation. The company serves primarily enterprise customers across verticals such as agriculture, government, financial services, retail, utilities, and more. Some example customers include 23andMe, Cornell University, Dropbox, and Linkedin. In December 2024, Boomi acquired Rivery, a data management startup which focuses on “end-to-end ELT (extract, load, transform) which covers key processes for medium and large enterprises.” The addition of Rivery expands Boomi’s direct competitive nature with OneSchema.
MuleSoft: Founded in 2006, MuleSoft is an enterprise data integration platform that was acquired by Salesforce in 2018 for $6.5 billion. Salesforce was focused on leveraging MuleSoft to more effectively integrate Salesforce’s disparate cloud products. The company serves customers such as AT&T, BP, and the Royal Bank of Canada.
Alteryx Design Cloud: Formerly known as Trifacta, the company was founded in 2012, and specializes in data wrangling, which involves cleaning, structuring, and enriching raw data into a desired format for analysis. The company reportedly attempts to focus on serving both technical and non-technical users with products across data wrangling, visual data profiling, and data governance. Trifacta was acquired by Alteryx in 2022 for $400 million and in June 2023 was rebranded to Alteryx Designer Cloud.
Talend: Founded in 2005, Talend provides a suite of data integration and management tools, including Talend Data Fabric that extends across data integration, data quality, data integrity and governance, and application / API integration. Talend’s product facilitates data integration, transformation, and governance across various sources and environments, supporting both on-prem and cloud deployments. After private equity firm Thoma Bravo acquired business intelligence tool, Qlik, for $3 billion in 2016 the firm then acquired Talend for $2.4 billion in 2021 and merged the two businesses. At the time, Talend had $350 million of revenue and 7K customers, such as ABInBev, AstraZeneca, and Domino’s.
Informatica: Founded in 1993, Informatica offers a range of data integration and management products, including Informatica PowerCenter, Informatica Intelligent Cloud Services, Informatica Data Quality, Informatica MDM, and Informatica Data Integration Hub. These tools support data integration, transformation, quality, governance, and master data management across on-prem and cloud environments. As of February 2025, Informatica had a market cap of $7.5 billion and in 2024 expected to generate revenue of $1.7 billion.
Embedded iPaaS
Workato: Founded in 2013, Workato is an Integration Platform as a Service (iPaaS) provider. The company offers over 1K integrations with business applications, such as Salesforce, Netsuite, Slack, Workday, etc. Workato has customers such as HP, Atlassian, and Adobe and, as of January 2021, Workato claimed to have over 7K customers. As of February 2025, the company had raised $415 million in total funding from investors such as Insight Partners, Altimeter, Battery Ventures, Redpoint, and others. In November 2021, the company was valued at $5.7 billion.
Tray: Founded in 2012, Tray is a unified iPaaS focused on automating business processes and activating ecosystem integrations. Tray’s product offers both a low-code workflow builder and a Connector Developer Kit to use APIs and SDKs to make integrations. As of February 2025, the company has customers such as Cvent, HackerOne, Eventbrite, and Udemy. As of February 2025, the company had raised $150 million of total funding from investors such as True Ventures, Notable Capital, and Spark Capital.
Adjacent Unified API
Beyond companies that are specifically managing comparable data transformations, OneSchema also has adjacent competitors that offer similar, but different offerings. In a May 2024 interview with Contrary Research, OneSchema co-founder Christina Gilbert explained the difference in the following language:
“With product and engineering teams, the primary companies we run into are unified APIs. Though, often these relationships make more sense as partnerships. We often land with them. They’re better at integrations, and we’re better at spreadsheets.”
Merge: Founded in 2020, Merge is a unified API with a focus on offering specific integrations to enterprise tools across HR, CRM, ticketing, ATS, etc. Where OneSchema focuses on normalizing full data exports via CSV, Merge integrates platforms directly for incremental updates to particular data. As of February 2025, Merge had raised $75 million in funding from investors such as Accel, Addition, NEA, and others.
Finch: Founded in 2020, Finch is an API for connecting to employment systems, such as HR, payroll, and benefits platforms. The company has customers like Secureframe* and Carta across use cases such as tax and compliance, financial insights, and 401k management. As of February 2025, Finch had raised $62 million in total funding from investors such as General Catalyst, Y Combinator, and Menlo Ventures.
Differentiation
Across all of these different competitors there are a number of different stage and sector focuses. For OneSchema, differentiation typically comes down to several key elements, as Christina Gilbert described in a May 2024 interview with Contrary Research:
“In terms of differentiation, there are three main drivers: (1) our validation layer; other players haven’t invested in addressing every edge case that can come up in a CSV, (2) the way you build integrations with OneSchema is truly non-technical users recording transformations on a spreadsheet instead of hiring analysts to build connections, and (3) errors in a file feed can be recovered by a non-technical user.”
Business Model
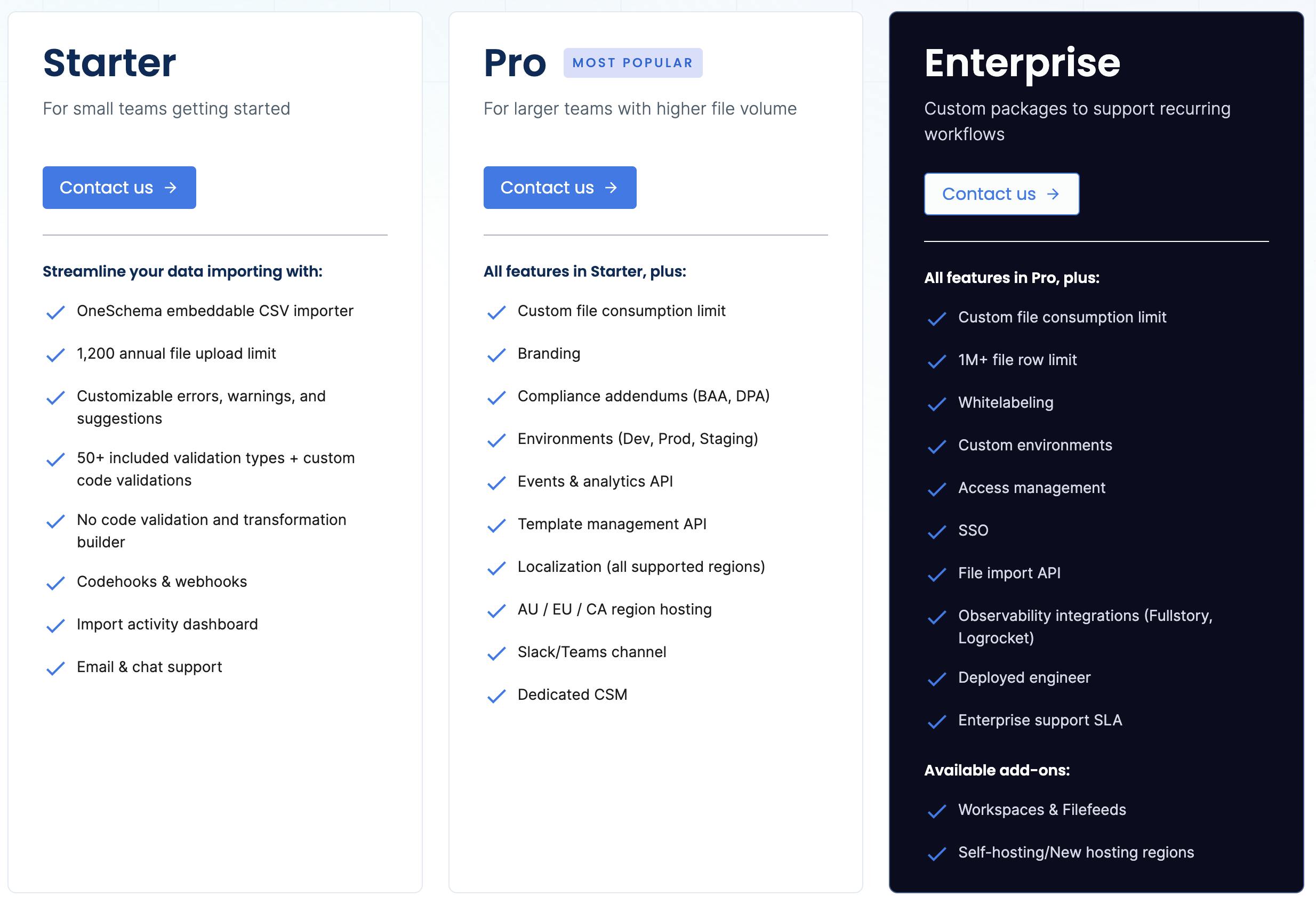
Source: OneSchema
OneSchema doesn’t publicly disclose its pricing, but in June 2024, the company shared with Contrary Research that the product is priced with a platform fee and consumption-based model. OneSchema’s usage-based metric is per successful file import. On its website, the company outlines three customer segments that vary based on the amount of support, analytics, and compliance robustness.
Traction
As of November 2022, OneSchema had grown to having 50 customers. In 2023, OneSchema was featured in Forbes Rising Stars list as part of the Cloud 100. As of June 2024, OneSchema shared with Contrary Research that the company has 130+ customers across North America, Europe, and Asia. These customers ranged from cloud 100 startups to publicly traded enterprises.
Valuation
As of February 2025, OneSchema has a raised a total of $6.4 million in funding. After participating in Y Combinator in 2021, OneSchema raised a $6.3 million funding round led by General Catalyst with participation from other investors such as Sequoia, Contrary, and Elad Gil. In addition, other investors included angels such as Wade Foster, the CEO of Zapier, Julianna Lamb, the CEO of Stytch*, and Steven Bartel, the CEO of Gem.
Key Opportunities
Enterprise Opportunity
As previously stated, OneSchema’s target customer has evolved from initially only focusing on mid-market companies to then expanding to address enterprise customers. In a May 2024 interview with Contrary Research, Christina Gilbert explained the difference this way:
“For mid-market tech companies, OneSchema saves them a few engineers’ time. But enterprises don’t have engineers. So these massive enterprise companies may have 30 people manually cleaning spreadsheets that OneSchema can replace.”
As OneSchema continues to penetrate into larger enterprises it will be addressing problems that, for some of the largest companies, represent tens of millions of dollars of spend and dozens of people to address manually. As a result, OneSchema will be able to increase the average contract size it can command, and be an even more valuable part of a larger company’s technology stack.
AI Transformations
The data normalization engine that represents the foundation of OneSchema’s product is a universal rules engine that is improved as a result of every CSV or other file type import that OneSchema processes. There is a network effect in that process that enables OneSchema’s product to continue to improve. As that data moat grows, it represents the potential for the company to broaden its use of AI in servicing customers. Andrew Luo, in a May 2024 interview with Contrary Research, explained the opportunity this way:
“We have a great set of labeled data to build an AI transformation set. Because we have these validation capabilities and a really robust set of validation elements, we also have the workflow engine upon which an AI transformation engine on top of spreadsheets would be powerful.”
Key Risks
Executing on Messaging
One of the complexities that OneSchema faces is the ability to address a number of different use cases as a horizontal tool. With use cases across management consulting, ecommerce, insurance, healthcare, and financial services, OneSchema needs to manage the process of balancing unique messaging that is specific enough to resonate for a specific vertical, but not too specific that it brands OneSchema to a specific vertical, like “spreadsheet transformations for healthcare.”
Competitive Landscape
Given the number of different segments and industries OneSchema is able to address, it opens the company up to competition with a number of different competitors. In particular, as OneSchema pushes more deeply into enterprise customers it will run into several 20+ year old companies that have become deeply entrenched in these larger businesses. OneSchema will have to demonstrate enough value to displace these legacy tools.
Summary
OneSchema is an embeddable CSV importer and validator that can automate the process of moving CSV files between organizations. The company was started to solve the complexity that comes from attempting to build an in-house CSV importer. In particular, the product addresses the difficulties in dealing with data edge cases. As a result of being a horizontal data tool, OneSchema finds itself addressing a number of different use cases across management consulting, ecommerce, insurance, healthcare, financial services, and more. While this creates a data advantage for OneSchema’s product to continue to improve, it also opens up the company to a wider variety of competitors. Going forward, OneSchema has the opportunity to establish itself as an enterprise-grade product with a sizable data advantage. As part of that advantage, OneSchema could more effectively leverage AI to service its customers.
*Contrary is an investor in OneSchema, Pave, Ramp, Secureframe, and Stytch through one or more affiliates


