Thesis
It has been over ten years since Marc Andreessen’s famous pronouncement that software was eating the world. From shopping and entertainment to healthcare and education, software has become a key component of nearly every aspect of life. Since the AI Boom in the late 2010s, however, artificial intelligence and machine learning have been eating software. Examples of this include Tesla’s Autopilot, Waymo’s driverless taxis, GitHub Copilot, TikTok content recommendations, or on-the-fly context-aware automated website guides like Ramp’s AI tour guide. The models that have enabled these advancements have required increased volumes of data for training. As Clive Humby pointed out in 2006, “Data is the new oil.”
One meaningful benefit of building AI applications has been the dramatic increase in the volume of data generated from both the digital and physical world. Through advances like computer vision, sensor fusion, robotics, and autonomous vehicles, the volume of physical data has increased significantly. However, in order to train models with these types of resources, the data needs to not just be available, but be organized.
A persistent issue with building AI/ML applications has been the lack of well-organized data necessary for developing models. This is a self-reinforcing cycle where initial data collection leads to improved AI models, enhancing user experience. Better user experiences attract more users, leading to further data collection. Over time, this cycle continually upgrades the quality of the AI model and the user experience. Data scarcity extends the timelines required to build AI models and reduces their accuracy. Without a strong dataset to train AI models, applications can exhibit decreased capabilities and increased vulnerabilities. Moreover, a lack of data can often prevent the application from being developed altogether. For example, in medical research, the limited availability of data for diagnosing rare diseases and conditions makes building an accurate AI application for identifying such conditions challenging and often unreliable.
That’s where Scale AI comes in. Scale AI’s vision is to be the foundational infrastructure behind AI/ML applications. The company began with data labeling and annotation used for building AI/ML models, tagging relevant information or metadata in a dataset to use for training an ML model. Scale AI’s core value proposition is built around ensuring companies have correctly labeled data to allow them to build effective ML models. By building comprehensive datasets, Scale AI provides the foundation for building AI/ML applications.
Founding Story
Scale AI was founded by MIT dropout Alexandr Wang (CEO) and Carnegie Mellon dropout and Thiel fellow Lucy Guo.
In 2015, Wang enrolled at MIT to study computer science, where he received perfect grades in his first year. Wang had the insight that artificial intelligence and machine learning were going to transform the world:
"First we built machines that could do arithmetic, but the idea that you could have them do these more nuanced tasks that required what we view as humanlike understanding was this very exciting technological concept."
To further explore AI, Wang started out with a fairly small-stakes problem: knowing when to restock his fridge. Obsessed with the grocery problem, Wang decided to build a camera inside his fridge to tell him if he was running low on milk. At this point, he realized that there was not enough data available so that he could train his system to quantify the contents of the fridge properly. He also noticed his peers weren’t building AI products despite their training because there was a lack of well-organized data available for them to develop models. This eventually led to the creation of Scale AI.
Wang extrapolated this problem out to the implications for AI in general, realizing that data would clearly be a meaningful hurdle. In order to bridge the gap between human and machine-learning capabilities, there was a need for accurately labeled datasets that could train AI models.
During this time, Lucy Guo was at Carnegie Mellon, studying computer science and human-computer interactions. In her second year, she applied for the Thiel Fellowship. The program awards $100K to help those motivated enough to build a business, on the condition that they drop out of school. In 2014, her senior year, she dropped out.
After her first company failed due to legal issues surrounding food delivery from non-commercial kitchens, she interned at Facebook and worked as a product designer at Quora and Snapchat. Wang and Guo met working togetther at Quora and concieved the idea for Scale AI shortly thereafter.
The Scale AI was accepted into Y-Combinator in 2016 and raised a $120K seed round. After exploring several aspects of the infrastructure needed for AI, the team narrowed its efforts down to autonomous vehicles. Self-driving cars needed humans to label the images so that the AI the cars used could be trained on those labeled images.
In he team attended Computer Vision and Pattern Recognition, an AI conference. There, according to Wang, they went “booth to booth with a laptop with a demo on it.” As the company grew, it expanded offerings into other industries serviced by AI, including satellite imagery, e-commerce, and others.
By 2018, the company had grown significantly, and both Wang and Guo were named to the Forbes 30 Under 30 list. At this time, Guo left Scale AI to start a venture capital firm called Backend Capital. According to Guo, the separation was due to a “division in culture and ambition alignment."
In June 2025, Meta finalized a deal to invest $14.3 billion into Scale AI in return for a 49% stake in the company. This same deal also committed Alexandr Wang to leaving Scale AI to lead Meta’s AI superintelligence lab. In the same month, Jason Droege was promoted from chief strategy officer to CEO.
Product
To understand the role of Scale AI, it's important to understand the lifecycle of building a machine-learning model for any given industry vertical. That process begins with raw data and leads to data engineering.
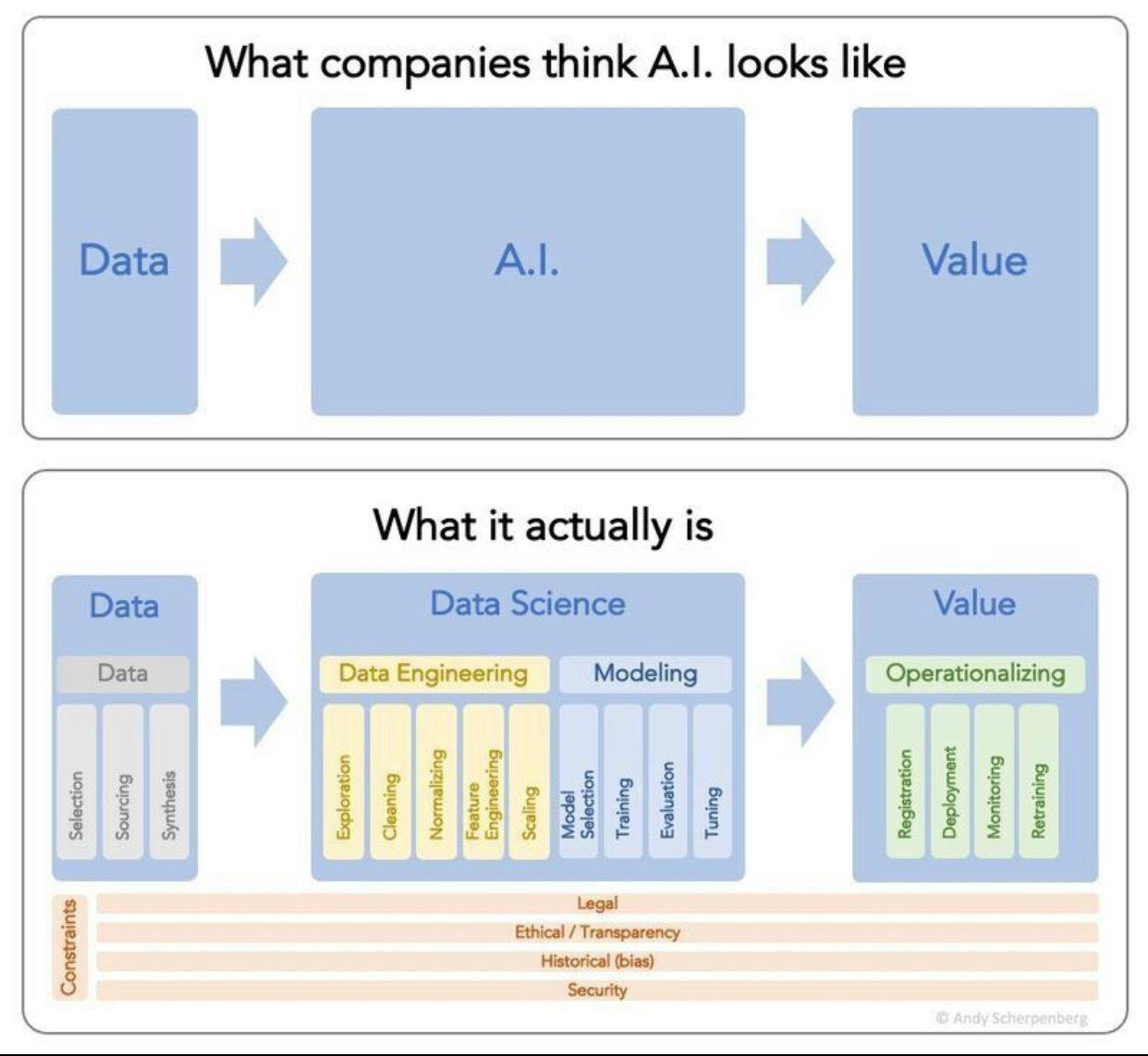
Source: Andy Scherpenberg
Scale AI’s core value proposition is built around the data engineering component of this lifecycle. Specifically, Scale AI helps companies with data annotation and labeling of “ground truth” data. This ground truth data refers to correctly labeling data in an expected format, such as tagging a picture of a cat as a “cat” or assisting in differentiating a dog from a cat in an image.
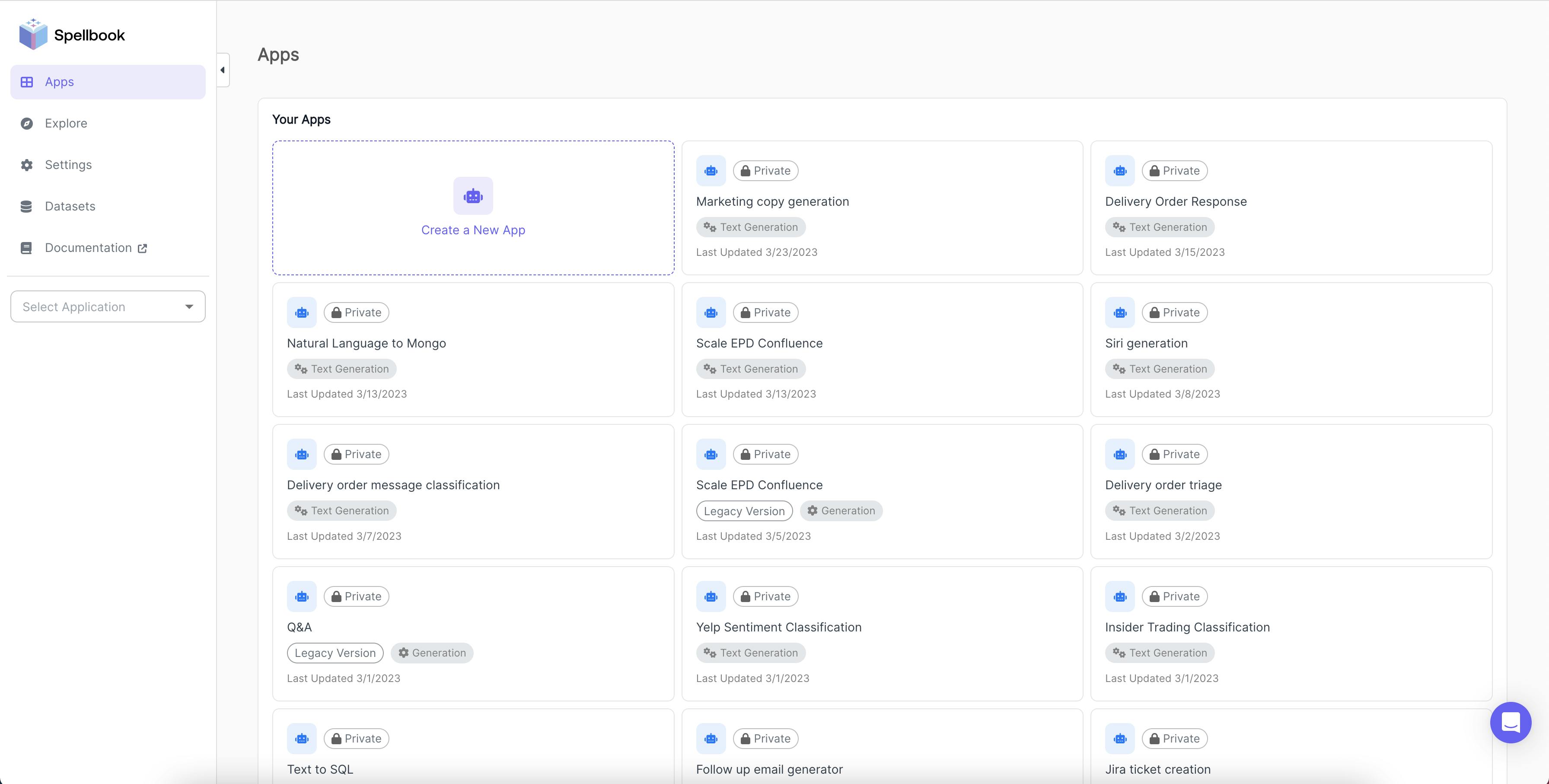
As of October 2025, Scale AI segments its products into three offerings, Build AI, Apply AI, and Evaluate AI, each with its own set of capabilities. Under Build AI is the Scale Data Engine, which services generative AI, government, and automotive applications. Apply AI consists of two products, Scale Donovan and the Scale GenAI platform. Evaluate AI provides access to Scale Evaluation, which is intended for model development, public sector, and enterprise use cases.
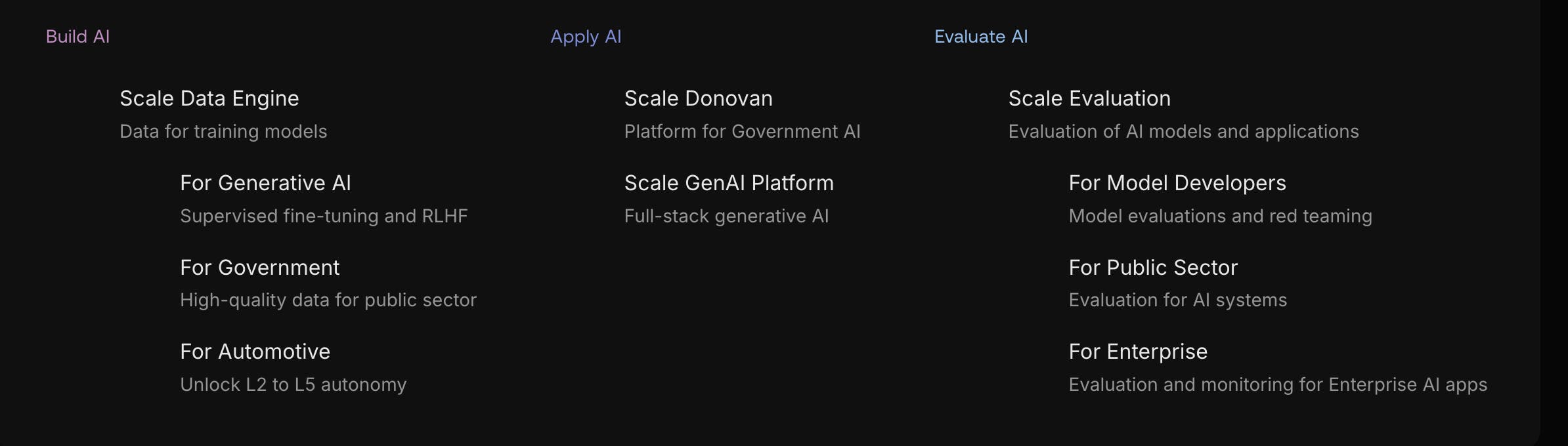
Source: Scale AI
Scale AI’s core products are Scale Data Engine, Scale Donovan, and Scale GenAI, while Scale Evaluation is embedded into the workflows of these three products.
Scale Data Engine
Scale AI’s core product is its data engine, which relies on a workforce of 240K people labeling data across Kenya, the Philippines, and Venezuela, managed through subsidiary RemoTasks. The data engine enables customers to collect, curate, and annotate data to train and evaluate models. Companies including Lyft, Toyota, Airbnb, and General Motors pay Scale AI to get high-quality annotated data labeled by human contractors, an ML algorithm, or a mixture of both.
Scale AI offers a comprehensive approach to data labeling by offering automated data labeling, human-only labeling, and human-in-the-loop (HITL) labeling, each with distinct advantages.
Automated data labeling utilizes custom machine learning models to efficiently label large datasets with well-known objects, significantly accelerating the labeling process. However, it requires high-quality ground-truth datasets to ensure accuracy and struggles with edge cases.
Human-only labeling, on the other hand, relies on the nuanced understanding and adaptability of human annotators, providing superior quality in complex domains like vision and natural language processing, albeit at a higher cost and slower pace.
HITL labeling combines both methods, where automated systems handle the bulk of the labeling and human experts review and refine the outputs. This hybrid approach ensures high accuracy and efficiency, combining the strengths of both automation and human expertise to produce superior data labels.
Scale AI annotates many different types of data, including 3D sensor fusion, image, video, text, audio, and maps. Image, video, text, and audio products are used across multiple industries, while 3D sensor fusion and map labeling are typically relevant for autonomous driving, robotics, and augmented and virtual reality (AR/VR).
As part of the data engine offering, Scale AI offers three distinct data annotation solutions tailored to different needs: Scale Rapid, Scale Studio, and Scale Pro.
Scale Rapid is an offering designed for machine learning teams to quickly develop production-quality training data. It allows users to upload data, set up labeling instructions, and get feedback and calibration on preliminary labels within a few hours, enabling a rapid scale-up of the data labeling process to larger volumes. As a self-serve platform with no minimums, users can upload their data, select or create annotation use cases, send tasks to the Scale AI workforce, and receive high-quality labeled data within hours, making it ideal for rapid project turnaround. Scale AI provides the necessary annotator workforce to ensure the data is labeled accurately and efficiently.
Scale Studio focuses on maximizing the efficiency of users' own labeling teams. It allows users to upload data, choose or create annotation use cases, use their own workforce, and monitor project performance, mainly used for organizations wanting to manage labeling internally and boost productivity. It provides a tool that tracks and visualizes annotator metrics and also provides ML-assisted annotation tooling to speed up annotations. It tracks metrics such as throughput, efficiency, and accuracy.
Scale Pro caters to AI-enabled businesses requiring scalable, high-quality data labeling for complex data formats. It features API integration, dedicated engagement managers for customized project setup, the ability to handle large volumes of production data, and guarantees the highest quality through service-level agreements (SLAs), providing a premium, fully-managed labeling experience.
The difference between Scale Studio/Pro and Scale Rapid is the approach to labeling the data. Scale Rapid requires that the data be annotated by Scale AI, while Scale Studio or Scale Pro requires the company to bring its own annotator workforce. However, each offering is under the umbrella of the Scale Data Engine.
Key Terms
Task: A task is an individual unit of work to be completed. Each task corresponds directly to the data that needs to be labeled. For instance, a separate task will be created for every image, video, or text that requires labeling.
Project: Within a given project, similar tasks can be organized based on instructions and use case. All tasks within a project will share the same guidelines and annotation rules. Multiple projects can exist for each use case. For instance, one project might be dedicated to categorizing scenes, while another focuses on annotating images. Each task is explicitly associated with a project to maintain organization.
Batches: On Scale Rapid, three types of batches can be launched for data labeling. A self-label batch allows users to test their taxonomy setup or labeling experience by creating a batch of data for themselves or team members to label. A calibration batch is a smaller set of tasks sent to the Scale AI workforce for labeling, providing labeler feedback, and enabling quick iteration on taxonomy and instructions; it undergoes fewer quality controls and is primarily used to refine labeling processes. Finally, a production batch involves scaling to larger volumes after iterating through calibration batches and refining quality tasks; it includes rigorous onboarding, training, and periodic performance checks for labelers to ensure high-quality labeling.
On Scale Studio, projects enable batches of data to be labeled by a customer’s in-house annotation team. On Scale Pro, batches can be used to further divide work within high-volume projects, associating tasks with specific internal datasets or marking tasks as part of a weekly submission.
Taxonomy: A taxonomy in data annotation is a structured collection of labels, known as annotations, and associated information defined at the project level. Annotations include boxes, polygons, events, text responses, linear scales, and rankings. Within a taxonomy, classes of annotation are combined with global attributes (information about the entire task), annotation attributes (details linked to a specific annotation), and link attributes (relationships between two annotations).
For example, a project may involve drawing boxes around all cats and dogs in an image, indicating the total number of cats and dogs. Each cat's box annotation would include an attribute for "sleeping or not sleeping," and each dog's box annotation would include a link attribute to indicate which cat it is looking at. Additionally, a global attribute would ask the labeler to specify the total number of cats and dogs in the image.
Source: Scale AI
Workflows
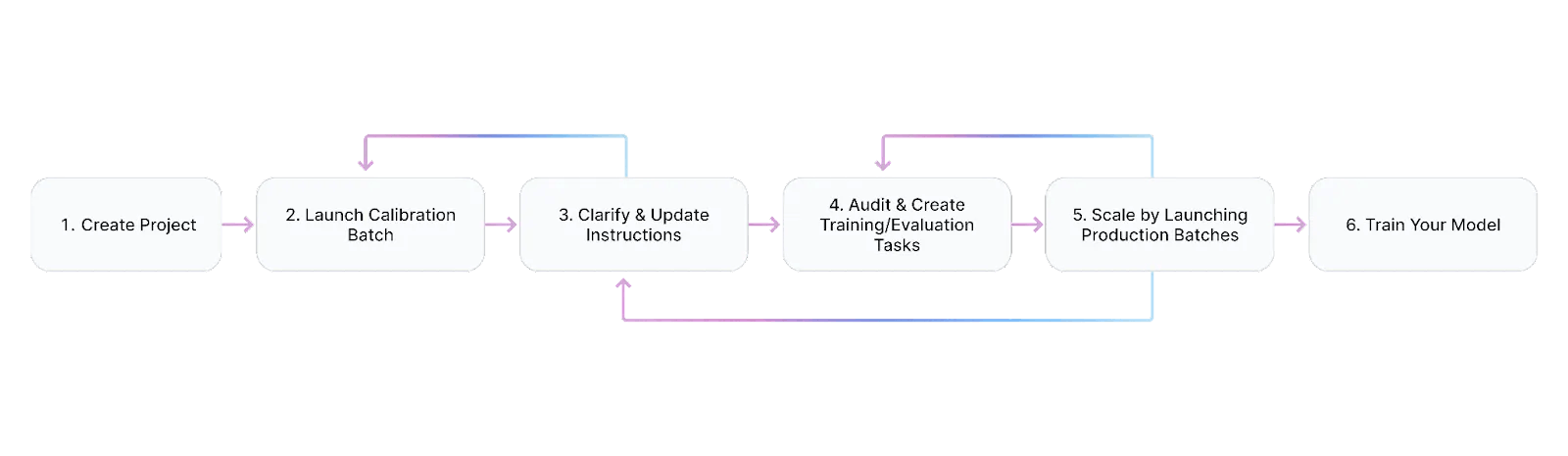
When initiating a project on Scale, a user will begin by selecting a template that fits the project’s use case or creating their own.
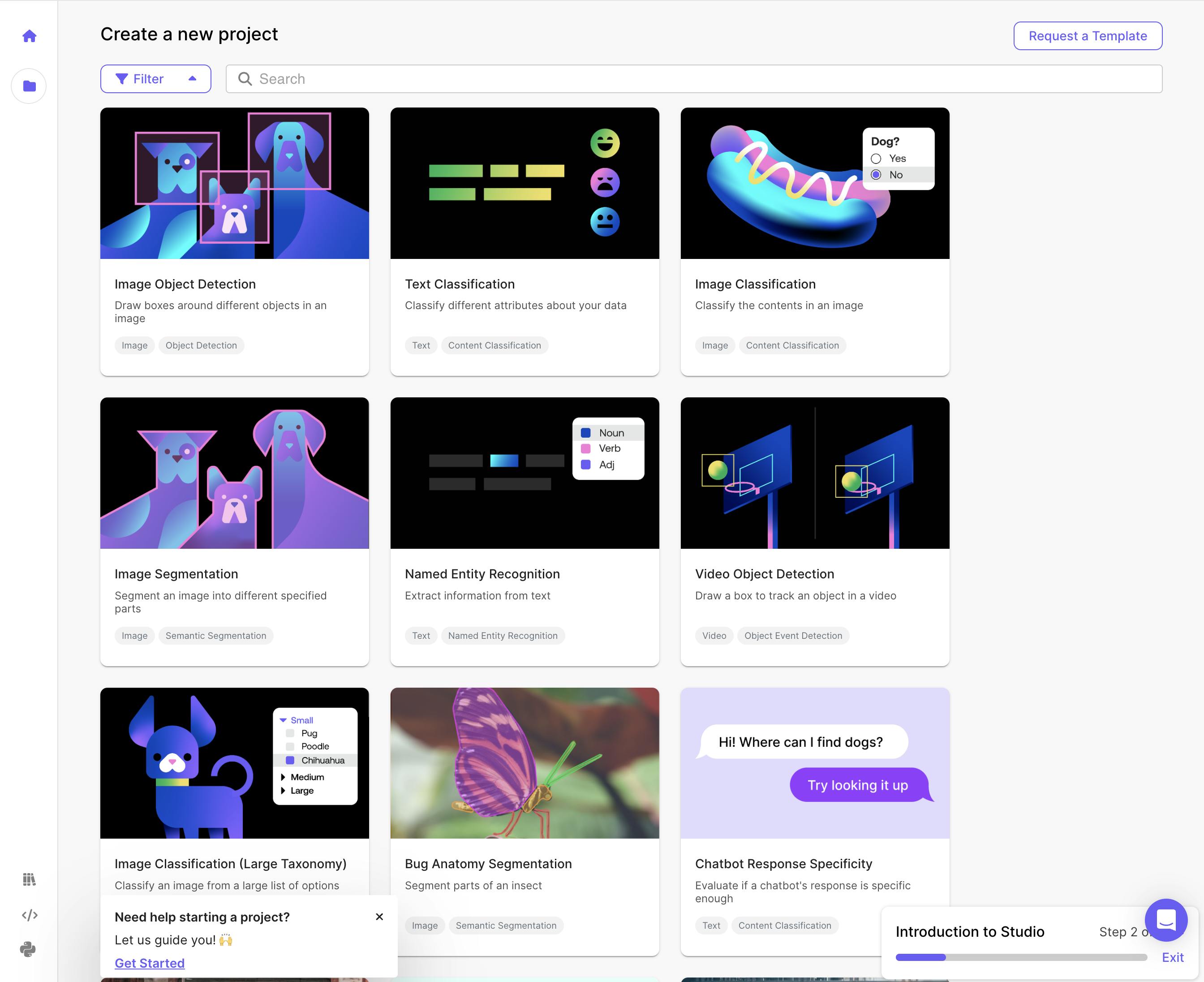
Source: Scale AI
Following this, the user must upload their data. The platform supports various data formats, including images, videos, text, documents, and audio. Once the data is uploaded, the user can choose from a list of available use cases tailored to their data format. Each use case provides a set of labels for building the project's taxonomy and a set of pipelines, which are sequences of stages that a task will go through before being delivered back to the user. Each project is assigned a single pipeline, and all tasks within the project will follow this same pipeline.
Upload Data: The user starts by uploading their data.
Select Use Case: The user chooses a use case relevant to their data format, which will define the available labels and pipelines.
Build Taxonomy: The user utilizes the labels provided by the use case to create a comprehensive taxonomy for the project.
Choose Pipeline: The user selects the pipeline that the project will use, ensuring that all tasks will follow the same sequence of stages.
Use Cases
Scale supports various data formats and use cases, including text (content classification, text generation, transcription, named entity recognition, content collection), images (object detection, semantic segmentation, entity extraction), video (object and event detection), PDFs/documents (entity extraction), and audio (same as text use cases except named entity recognition).
Object Detection: Comprehensive annotation for 2D images supports various geometric shapes, such as boxes, polygons, lines, points, cuboids, and ellipses. This task type is ideal for annotating images with vector geometric shapes.

Source: Scale AI
Source: Scale AI
Once a user selects a use case, they are prompted to create a taxonomy via a set of labels and attributes. These labels and attributes can be added via a visual label maker or a JSON editor for the API.

Source: Scale AI
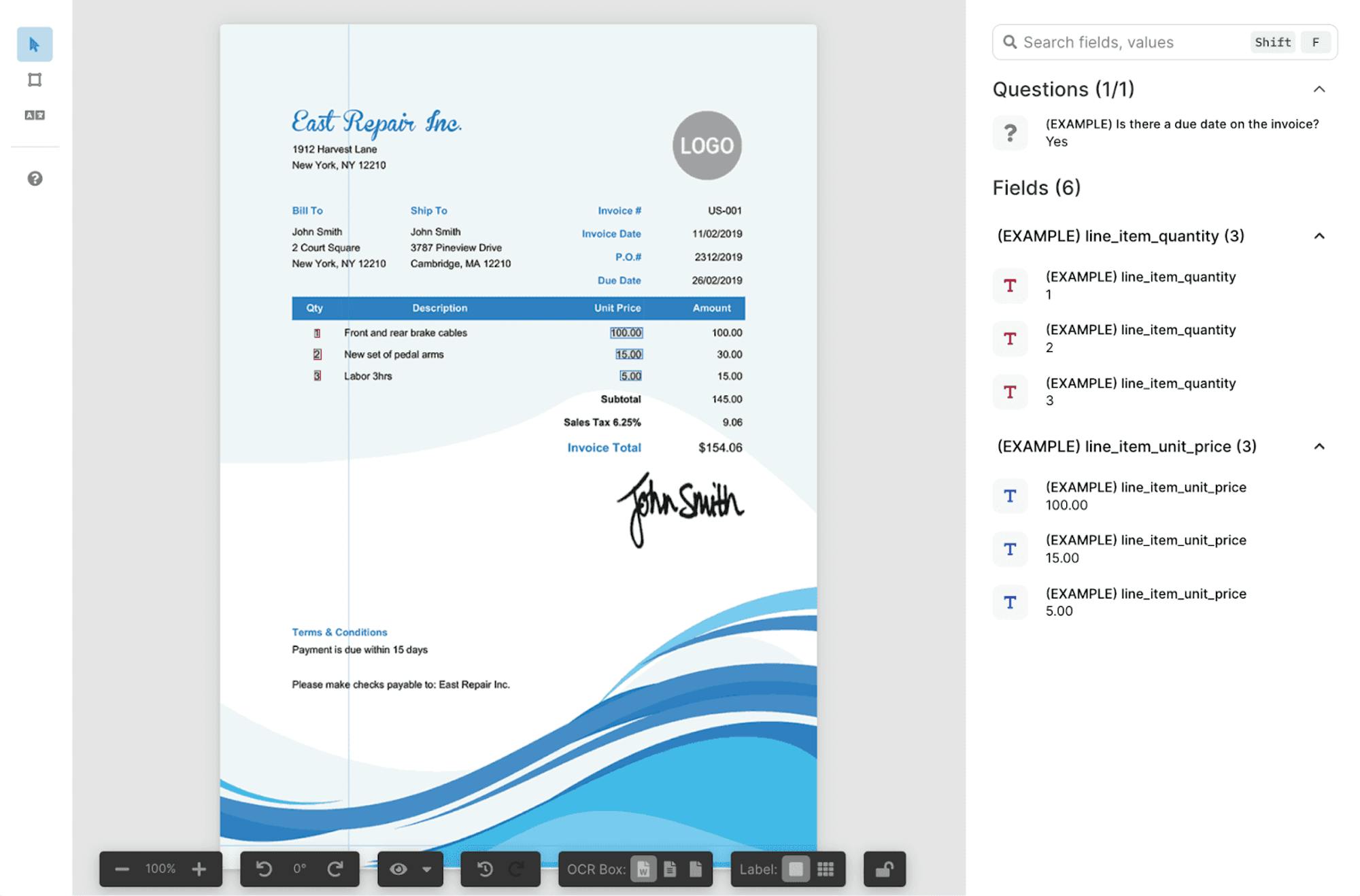
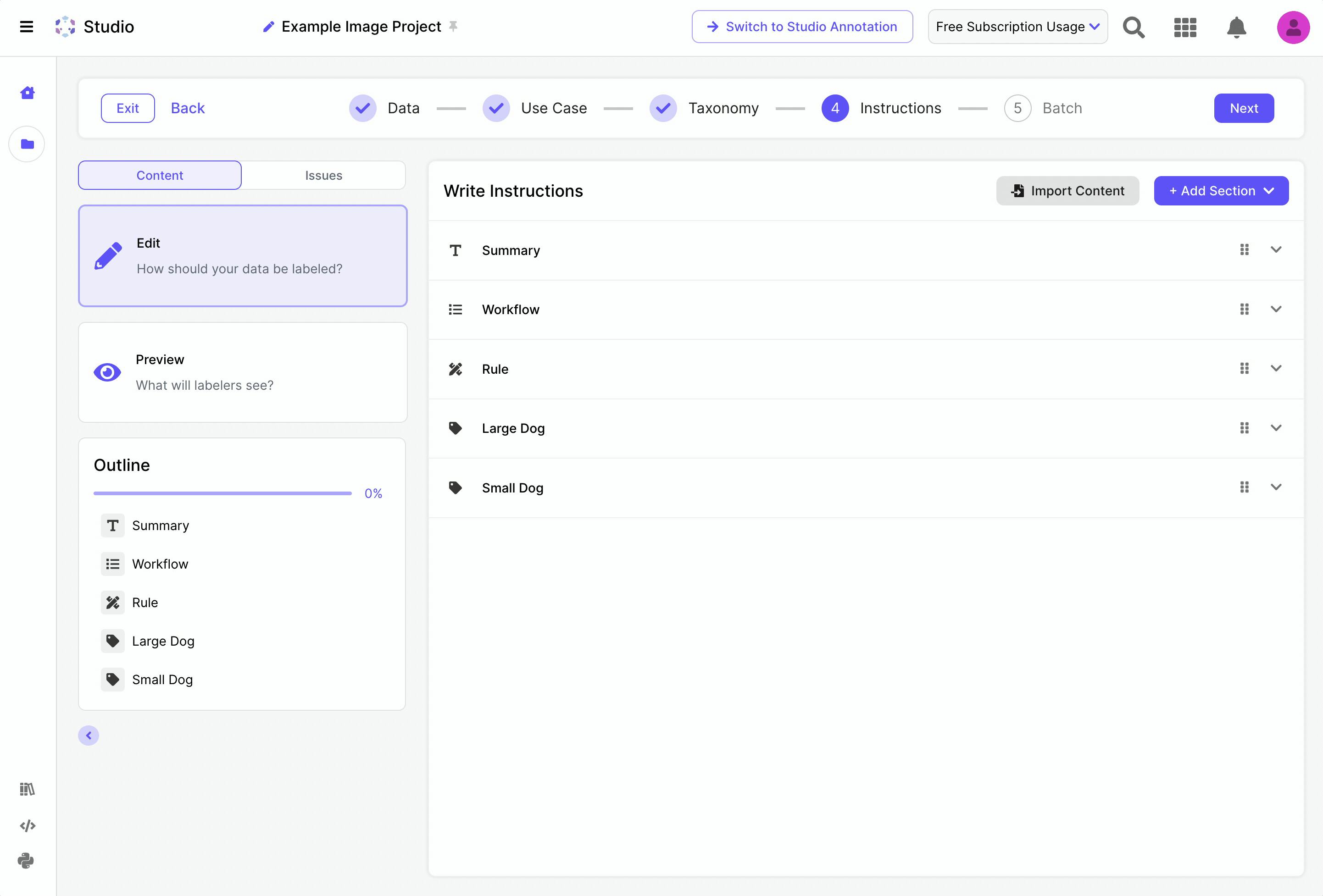
Instruction Writing
These instructions guide the labelers on how to handle each task accurately. After creating the taxonomy, an auto-generated instructions outline is created. In each case, whether the project is custom or based on a template, it includes the following sections:
Summary: Introduce the task, providing useful context like scenery, number of frames, objects to look for, and any unusual aspects.
Workflow: Provide a step-by-step guide on task completion, noting initial observations, deductive reasoning, and annotation impacts.
Rules: Describe annotation rules applicable to multiple labels or attributes, including well-labeled and poorly-labeled examples.
Label/Attribute/Field-Specific Sections: Detail unique rules with examples for each label/attribute/field.
Adding Examples: Additional well-labeled and poorly-labeled examples, highlighting differences.
Source: Scale AI
Calibration & Self-Label Batches
After setting up the project, taxonomy, and instructions, the user can proceed with one of the following:
Launch a Calibration Batch: This batch is reviewed by Scale AI labelers who provide feedback on the instructions and deliver the first set of task responses. This step helps identify discrepancies between the instructions and the task responses, allowing the user to refine their instructions.
Launch a Self-Label Batch: This option allows the user to test their own taxonomy setup and experience labeling on the Rapid platform firsthand.
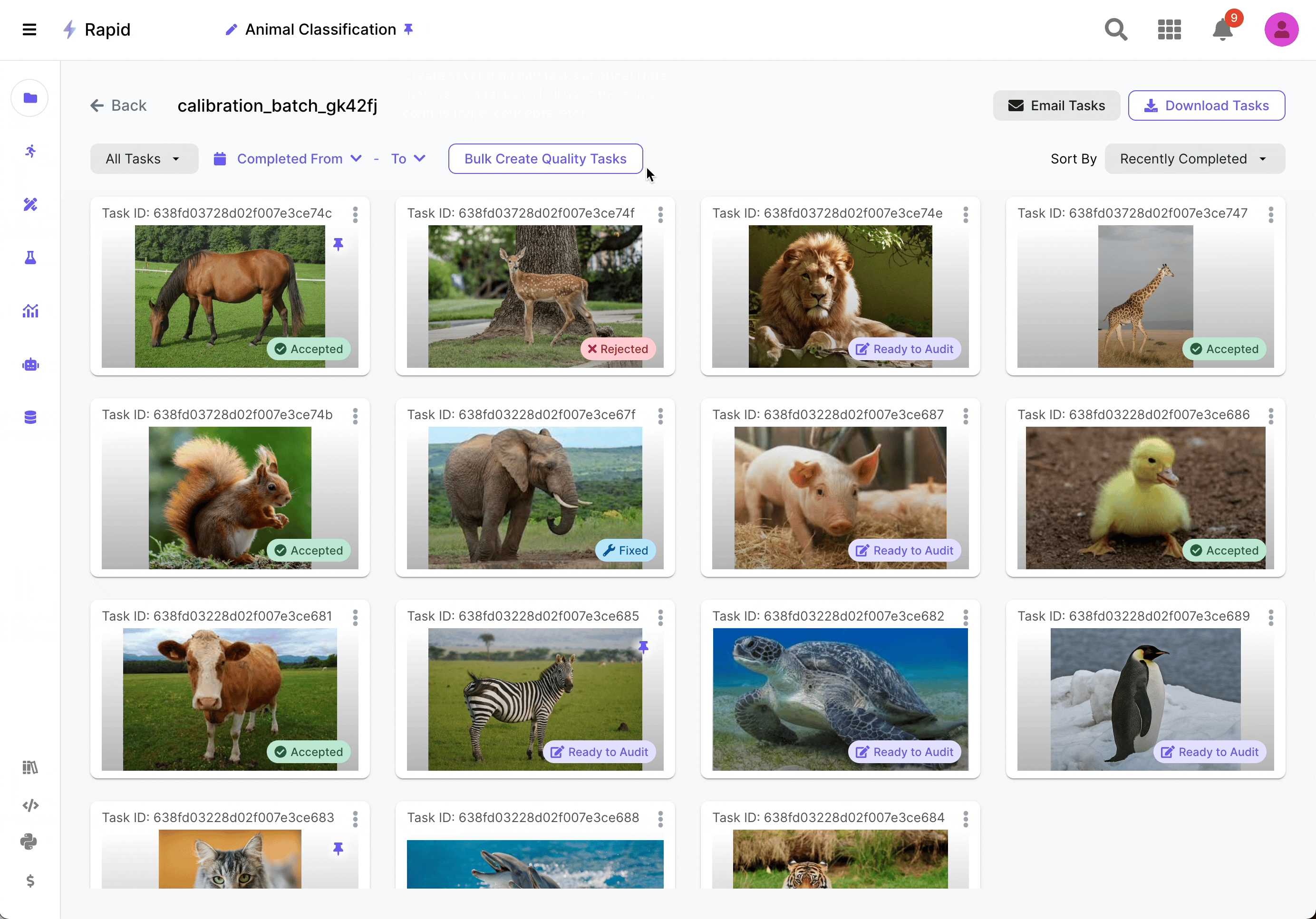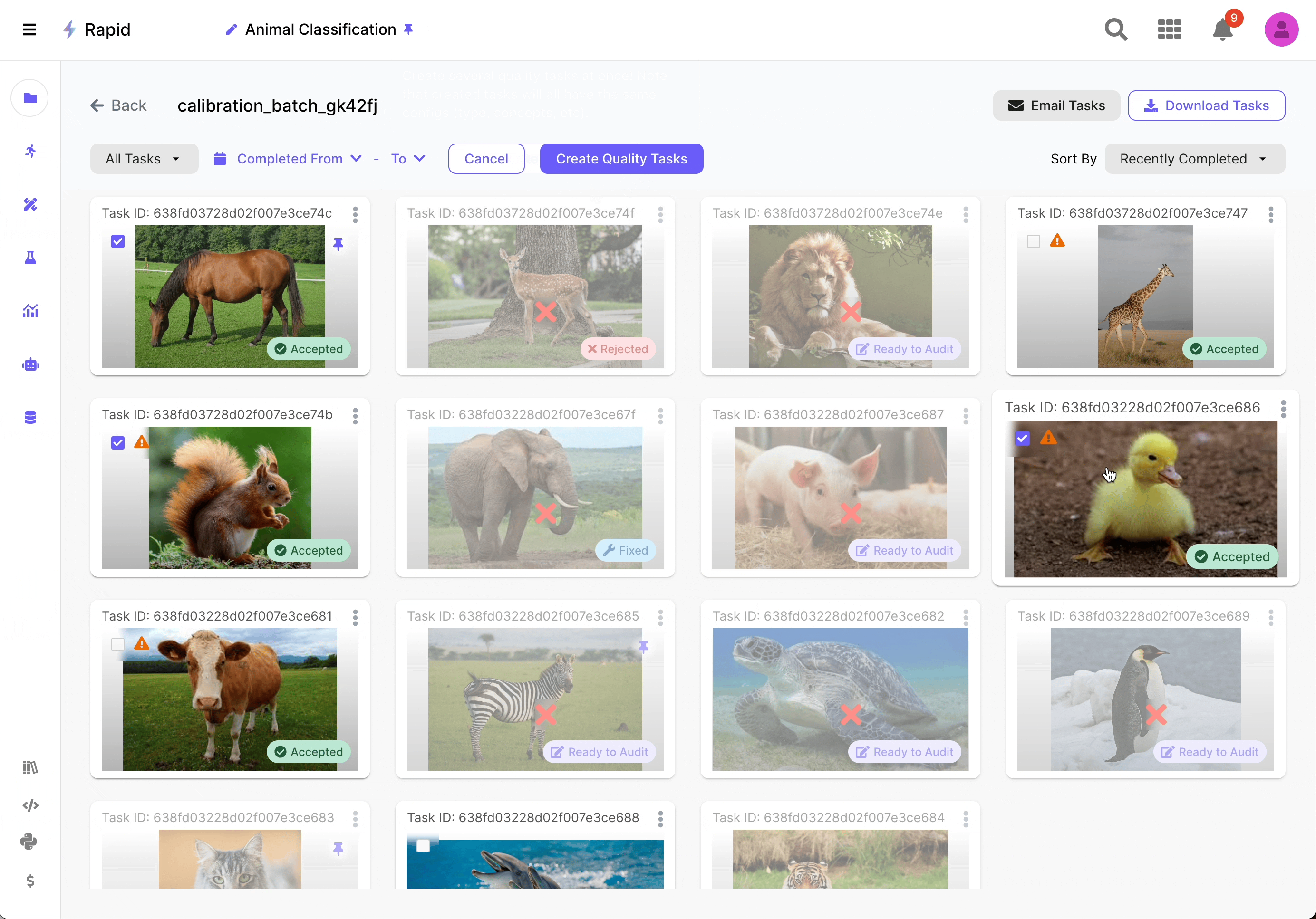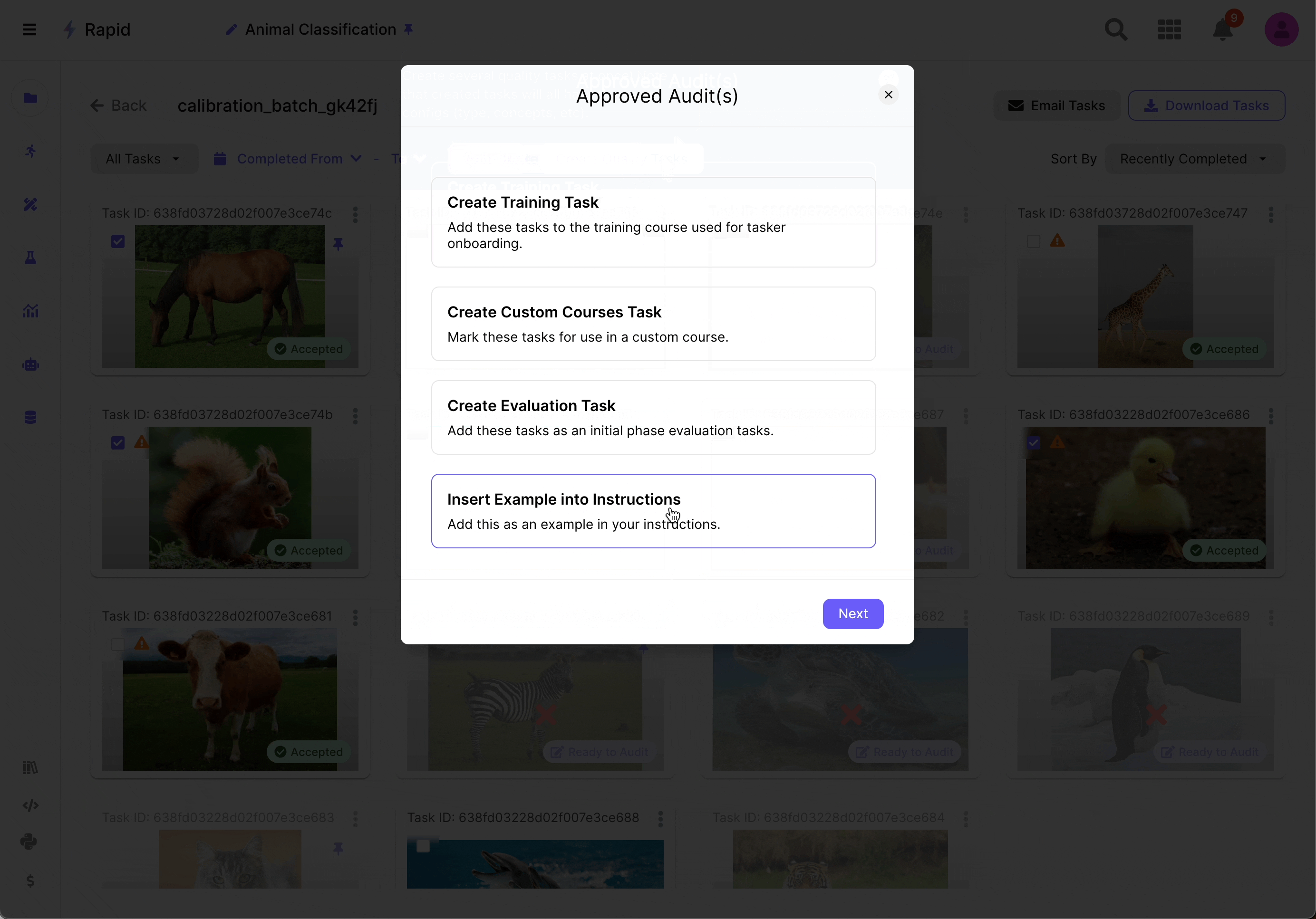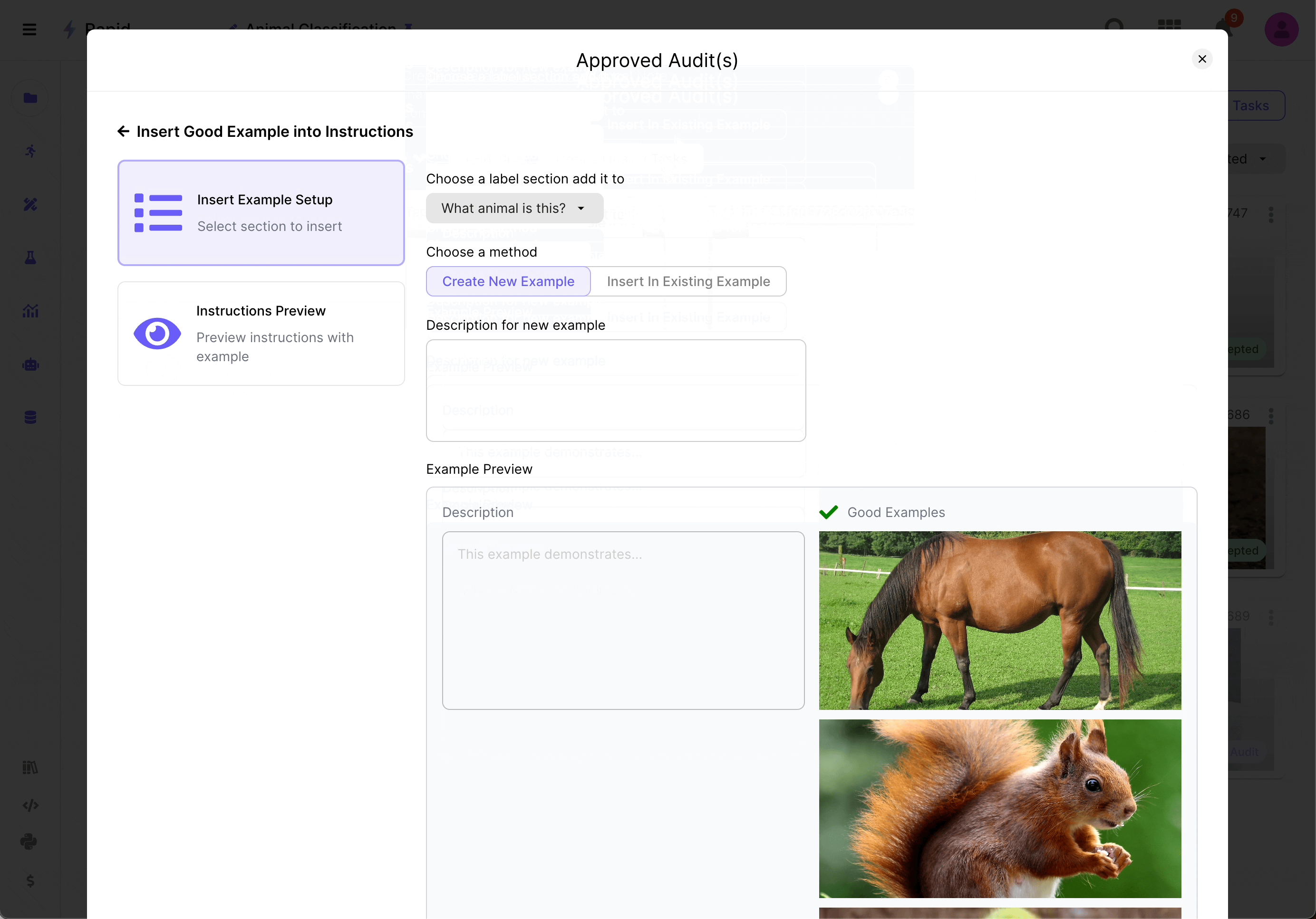
Auditing & Improving
Once feedback from the calibration batch is received, the user analyzes the discrepancies and improves their instructions. During the auditing process, the user can use the labeled tasks to create examples embedded in the instructions and quality tasks to enhance the overall project setup.
Source: Scale AI
Project
Once a project has been created, there are different views that a user can interact with. In the main view, a user is able to see the definition of the project, and each its tasks, labels, and instructions.
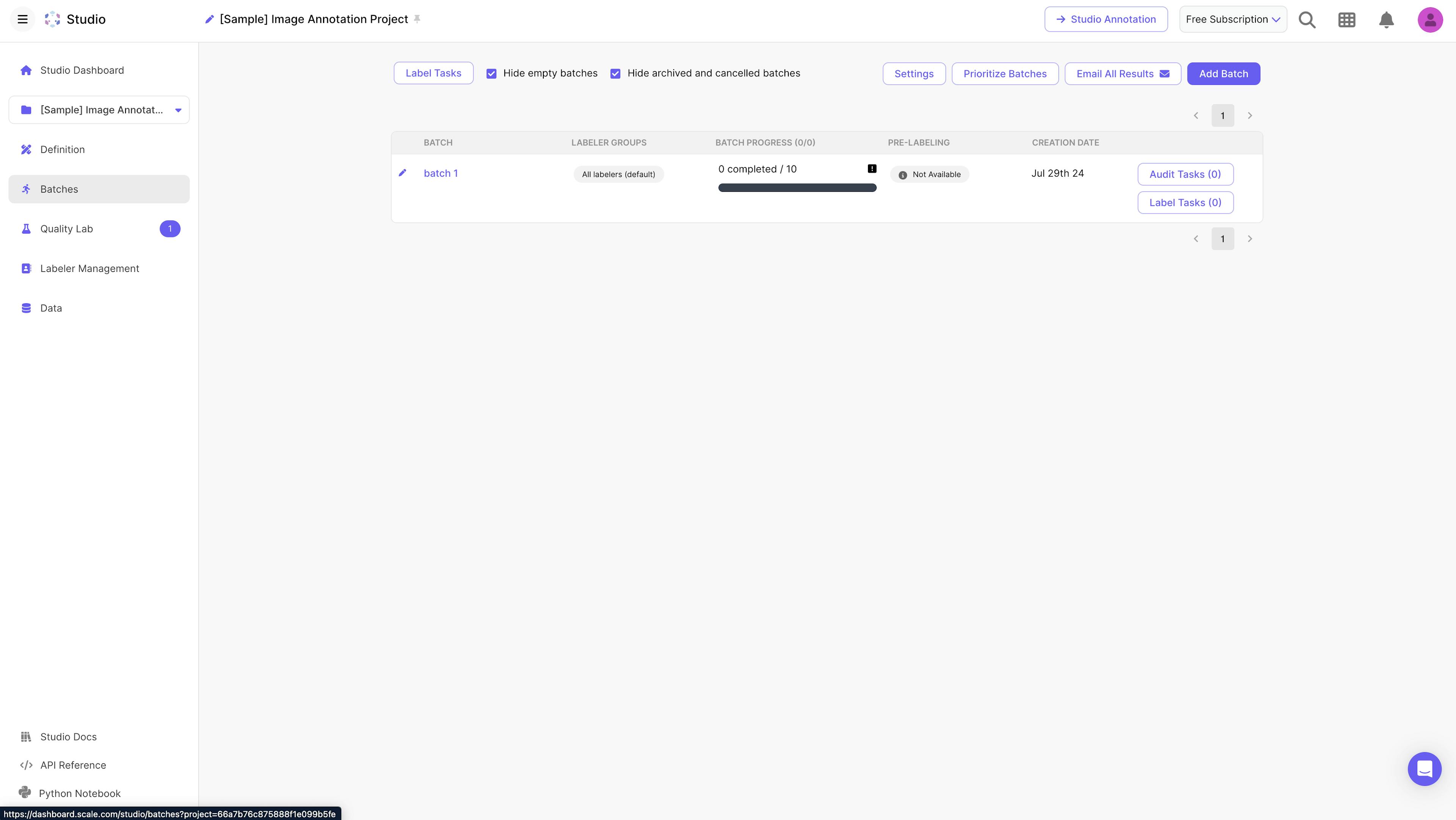
Source: Scale AI
Under the batches view, a user is able to see the in-progress batches of data that are to be annotated or completed. The labelers refer to those who have been assigned the task, a group or an individual user, depending on the task configuration. The percentage completed refers to the number of tasks that are done, this can be expanded to individual tasks to be addressed.
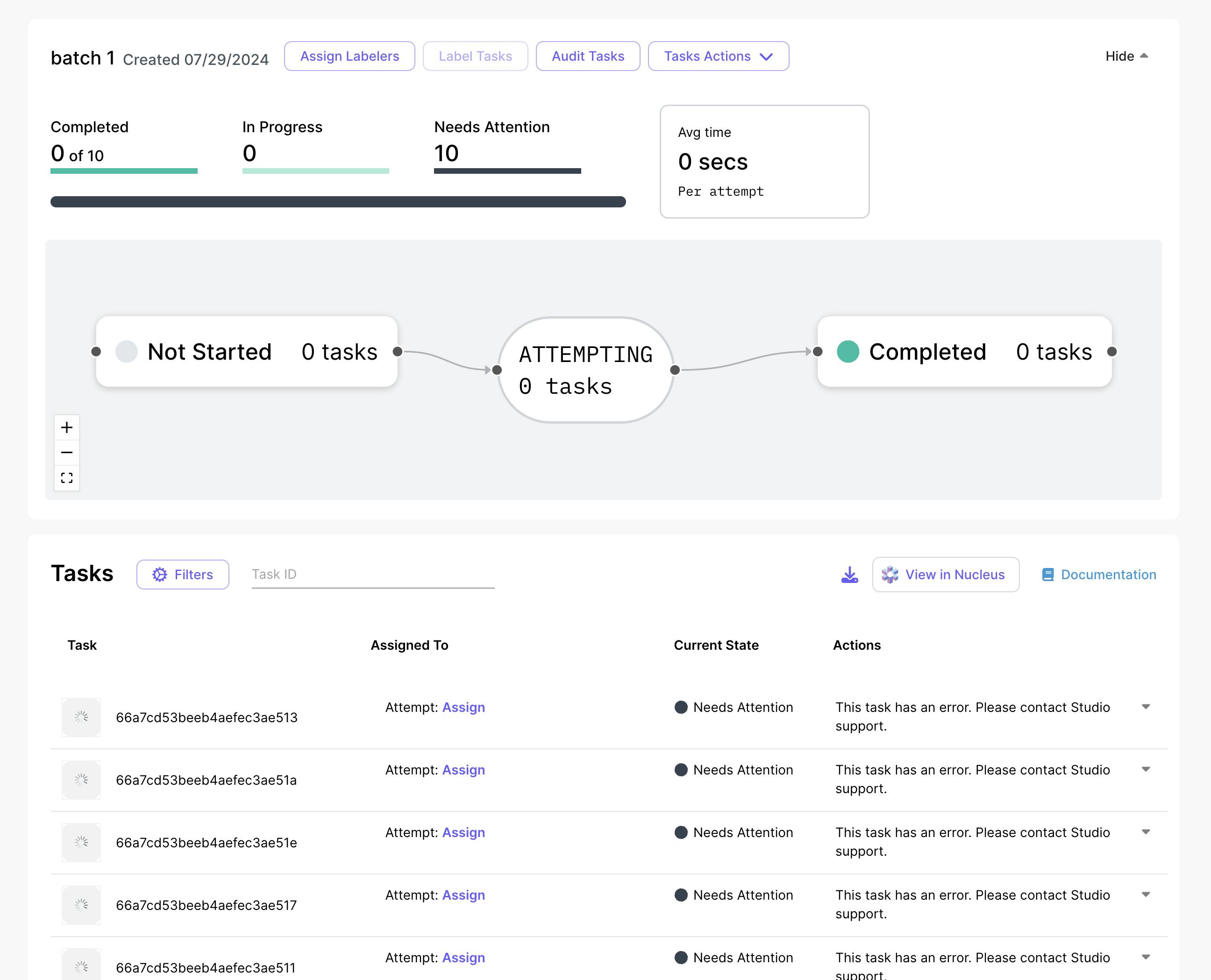
Source: Scale AI
The quality lab is a way to evaluate tasker accuracy and view other task-related statistics. Tasks can be audited individually or within a date range. An admin can also set up training tasks which can be used to help onboard onto the project.
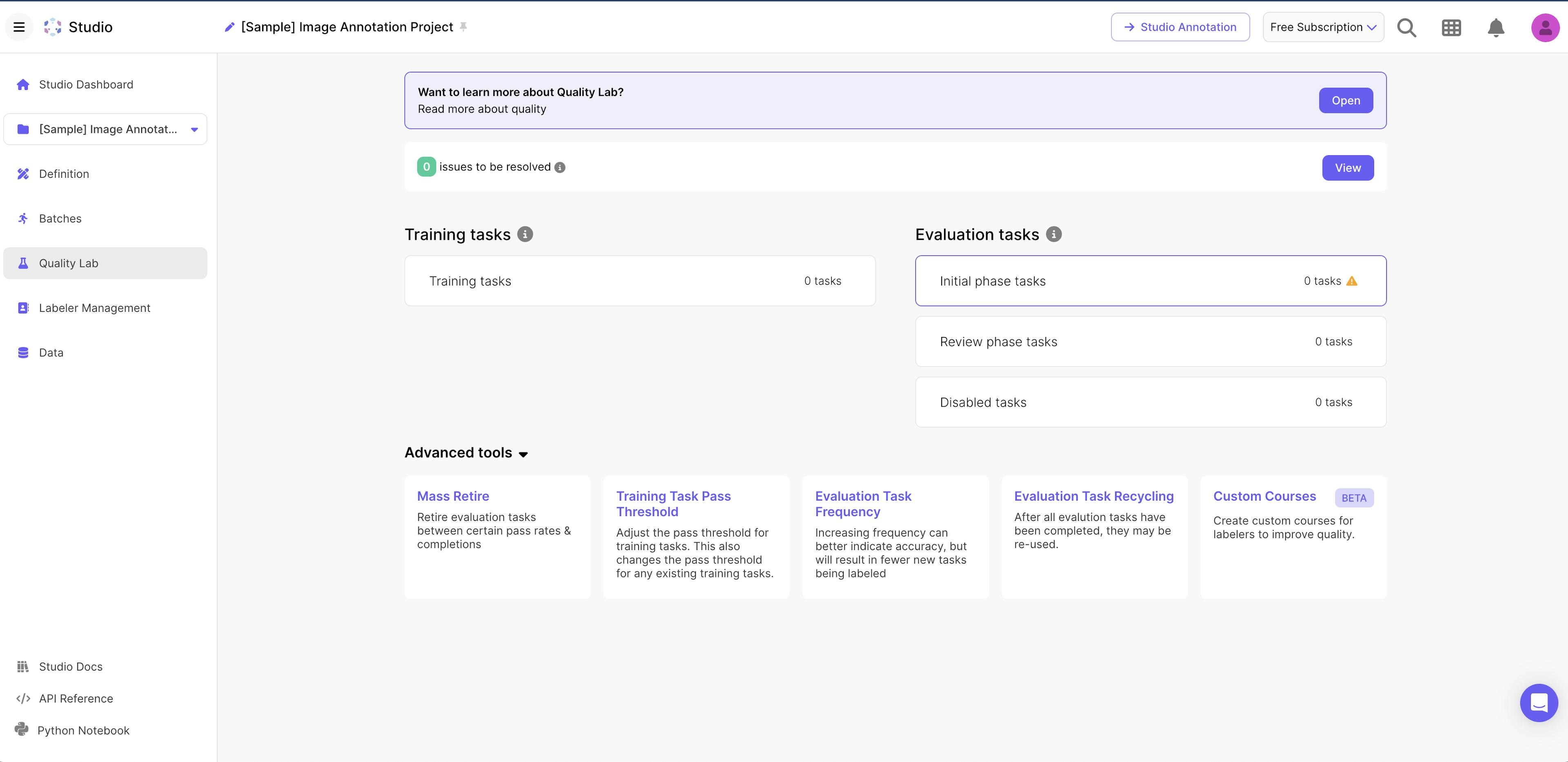
Source: Scale AI
Scale also offers more advanced tools to support completed tasks, including:
Mass retiring: Retire evaluation tasks that fall between certain pass rates and completion levels.
Training task pass threshold: Adjust the pass threshold for training tasks.
Evaluation Task Frequency: Increasing the frequency of evaluation tasks can improve accuracy.
Evaluation Task Recycling: Completed evaluation tasks can be reused.
Custom Courses: As of October 2025, this feature is in Beta. This is the ability to create new courses for labelers to improve the quality of their tasks.
Nucleus
In August 2020, Scale AI launched Nucleus, a “data debugging SaaS product.” Nucleus provides advanced tooling for understanding, visualizing, curating, and collaborating on a company’s data. Specifically, Nucleus allows for data exploration, debugging of bad labels, comparing accuracy metrics of different versions of ML models, and finding failure cases. This product is also available under the Scale Data Engine offering.

Source: Not Boring
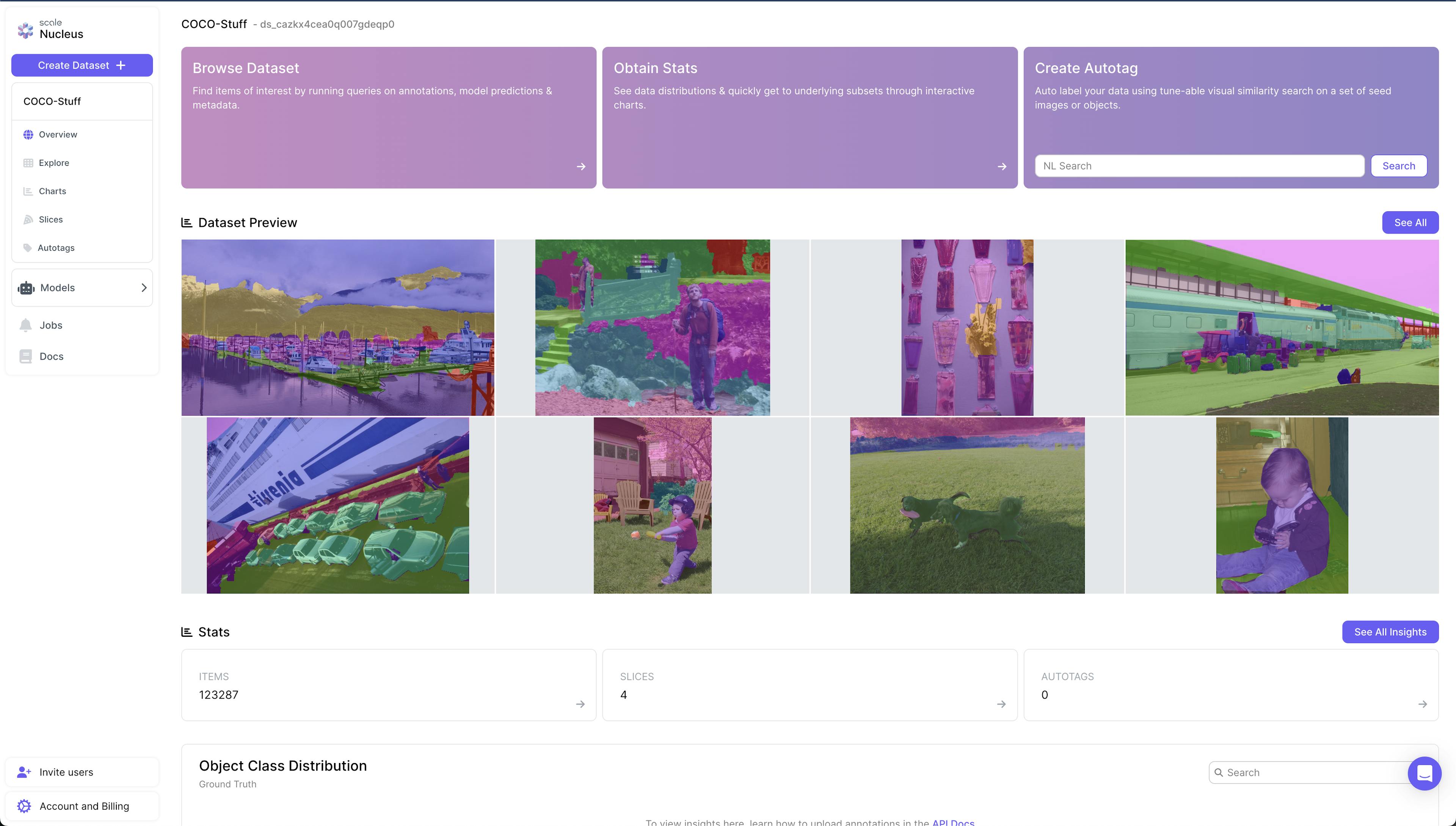
Scale Nucleus is a dataset management platform that helps machine learning teams build better datasets by visualizing data, curating interesting slices within datasets, reviewing annotations, and measuring model performance. By integrating data, labels, and model predictions, Nucleus enables teams to debug models and improve the overall quality of their datasets.
Source: Scale AI
The Nucleus dataset dashboard contains all the datasets associated with a user. These datasets can be created by importing images/tasks that a user already has access to in Scale, via the command line interface the platform’s UI. As a user clicks into a dataset, a dashboard view provides an overview of the contents and statistics associated with the dataset. These datasets can be classified as one of three types: image dataset, video dataset, or lidar dataset. Once the dataset's contents are uploaded, Nucleus supports uploading metadata which associates each dataset item with a scene, ground truth annotation model prediction, and segmentation mask.
Source: Scale AI
Under the explore tab, a user can see all the images and elements that belong to the dataset. In this view, a user will also see the type of annotation that is being applied to the dataset items: a geometric annotation, segment annotation, or category annotation.
When any of dataset element is selected, item properties, metadata, display of the annotations, or effects applied to the item are displayed on the right of the screen.
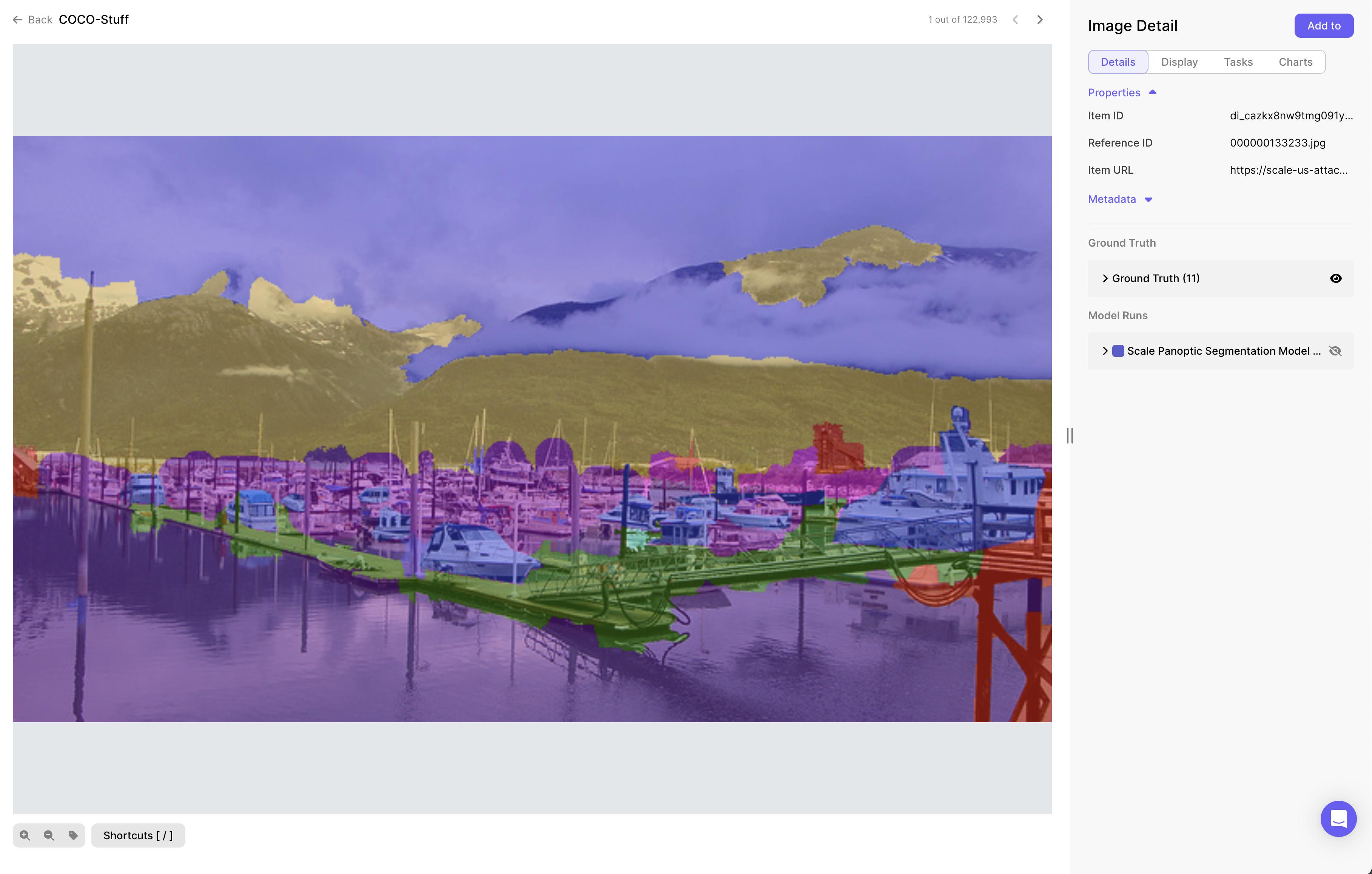
Source: Scale AI
The Nucleus query bar filters dataset items or annotations based on the given conditions, which can also be combined with AND or OR statements. For all image datasets, natural language search is also available (akin to what users would type in a Google search). Unlike structured querying that depends on annotations, autotags, or predictions, natural language search allows users to search their datasets using plain English. Users can also search by selecting an image and clicking “Find Similar”.
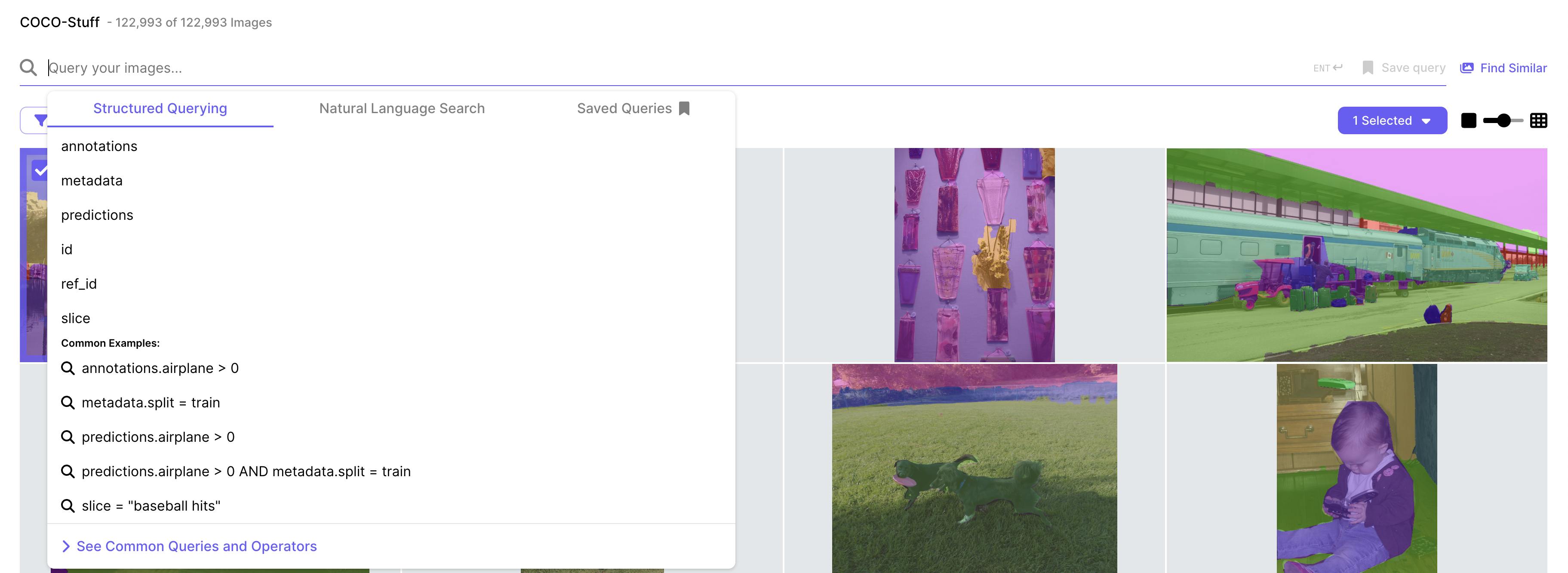
Source: Scale AI
Autotag is a machine learning feature that adds refined visual similarity scores as metadata to images or objects within a dataset. It starts with an initial set of example items to seed the search.
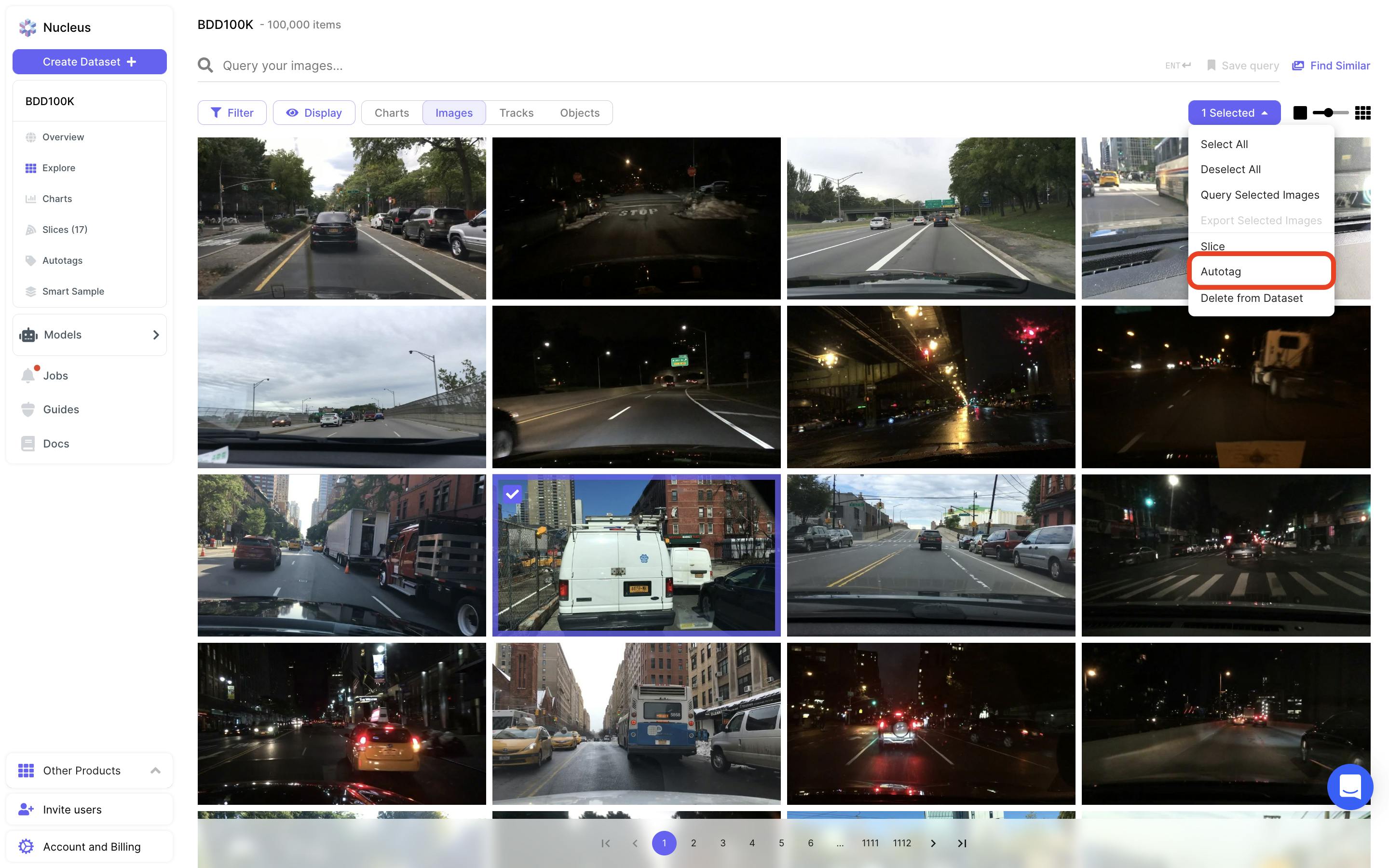
Source: Scale AI
Through multiple refinement steps, the search is fine-tuned by identifying relevant items from the returned results. Once the search is finalized, Autotag commits the metadata, assigning search scores (the higher, the more relevant) to the top 20K most relevant items in the dataset. These items can then be queried within the Nucleus grid dashboard.
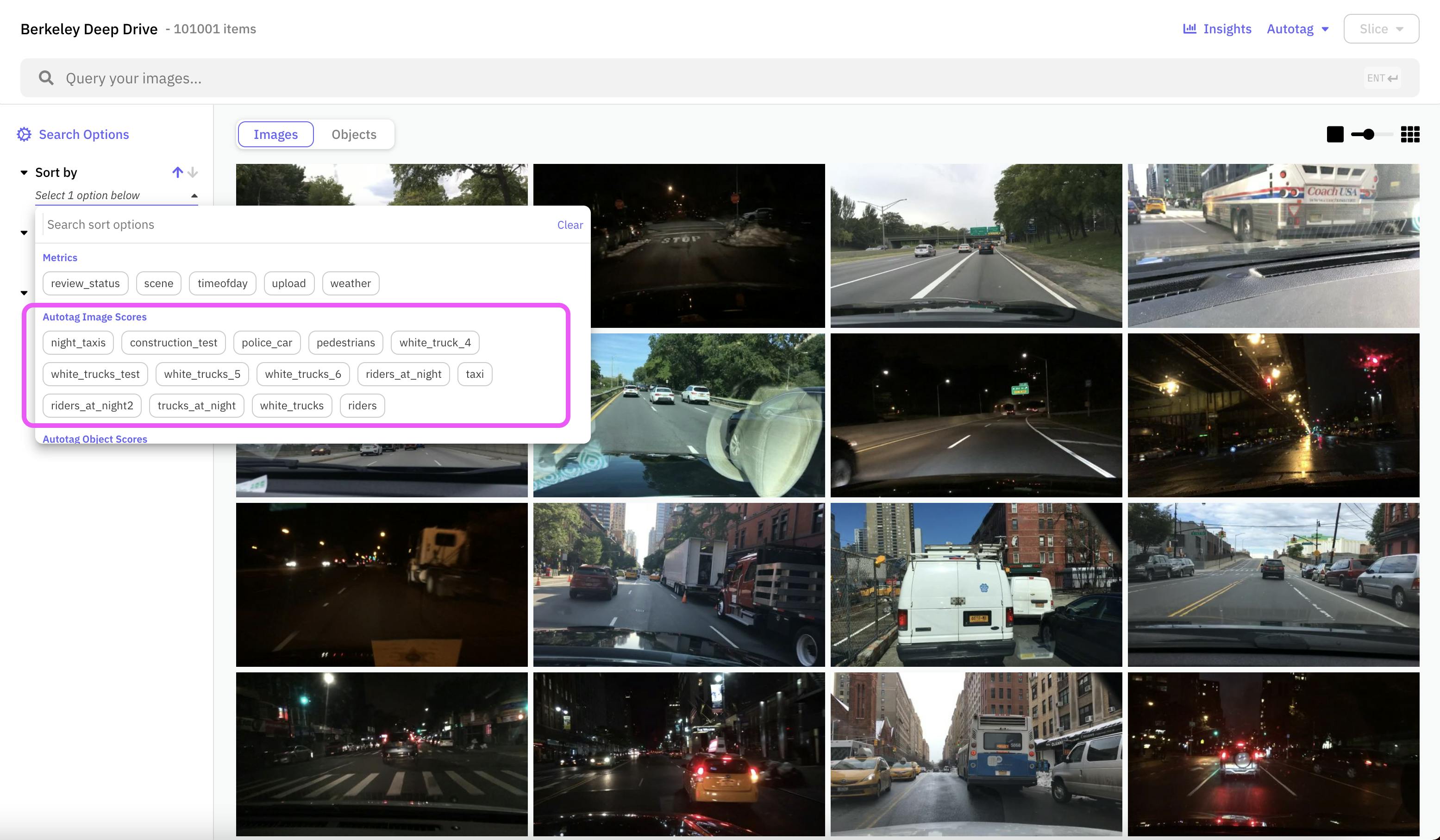
Source: Scale AI
Models
In Nucleus, models represent actual models in the inference pipeline. There are two types of models:
Shell Models: These are empty models without associated artifacts. They are used to upload model predictions into Nucleus, suitable for when inference is done externally and only the results are needed in Nucleus.
Hosted Models: These are real models with associated artifacts (e.g., a trained TensorFlow model). They are used to host models and run inference on a chosen dataset in Nucleus, with predictions automatically linked to the hosted model.
Source: Scale AI
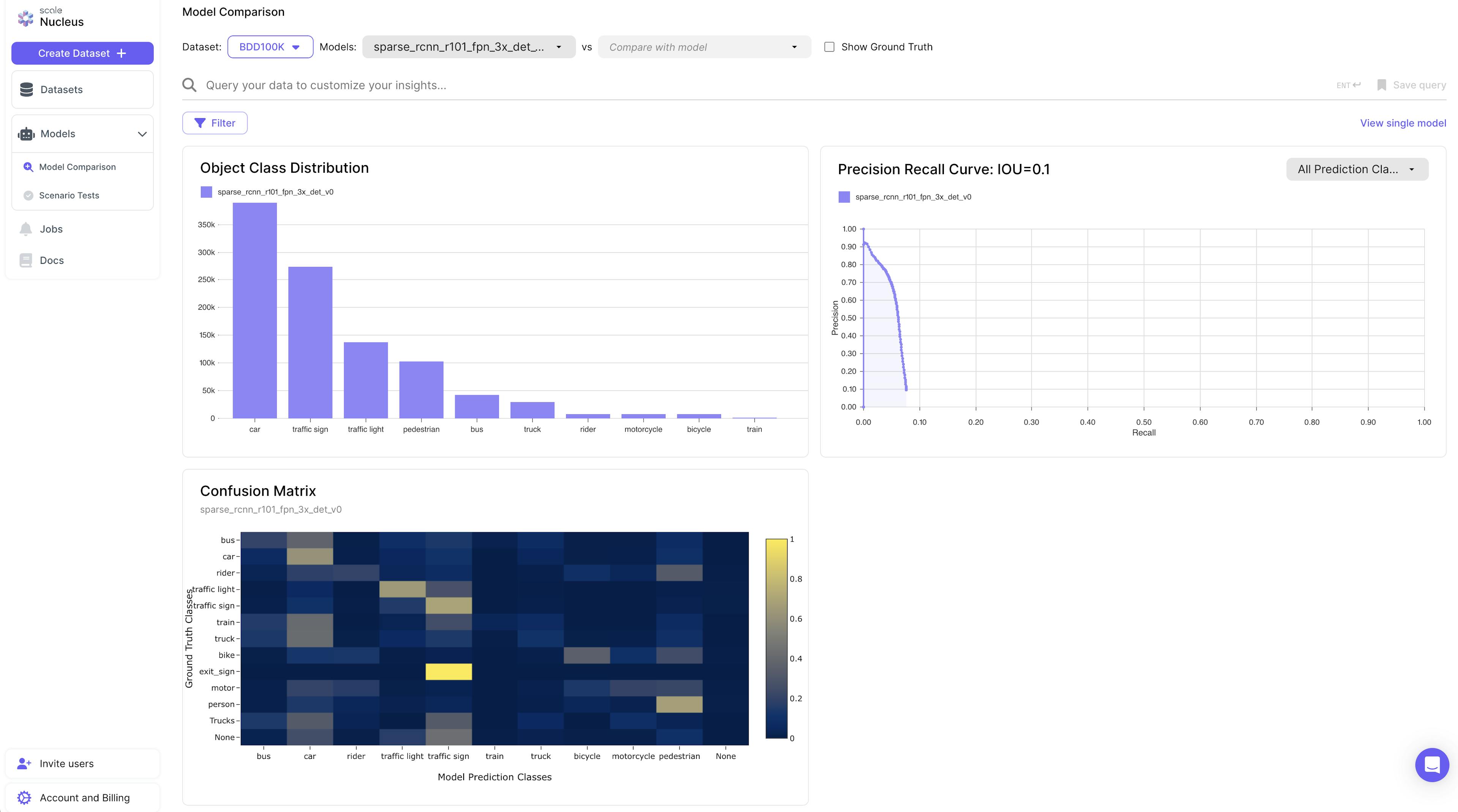
Under the Models View, a user will see additional information and graphs including a precision-recall curve and a confusion matrix.
Source: Scale AI
A precision-recall curve offers a detailed view of a model's performance, showing the tradeoff between precision and recall:
High Recall, Low Precision: The model returns many results, but many are incorrect.
High Precision, Low Recall: The model returns few results, but most are correct.
High Precision and High Recall: The model returns many results, all correctly labeled.
The balance between precision and recall depends on the application's needs. For example, in cancer detection, high recall is crucial to avoid missing cancerous tumors. In contrast, SPAM filters prioritize high precision to avoid misclassifying important emails as SPAM.
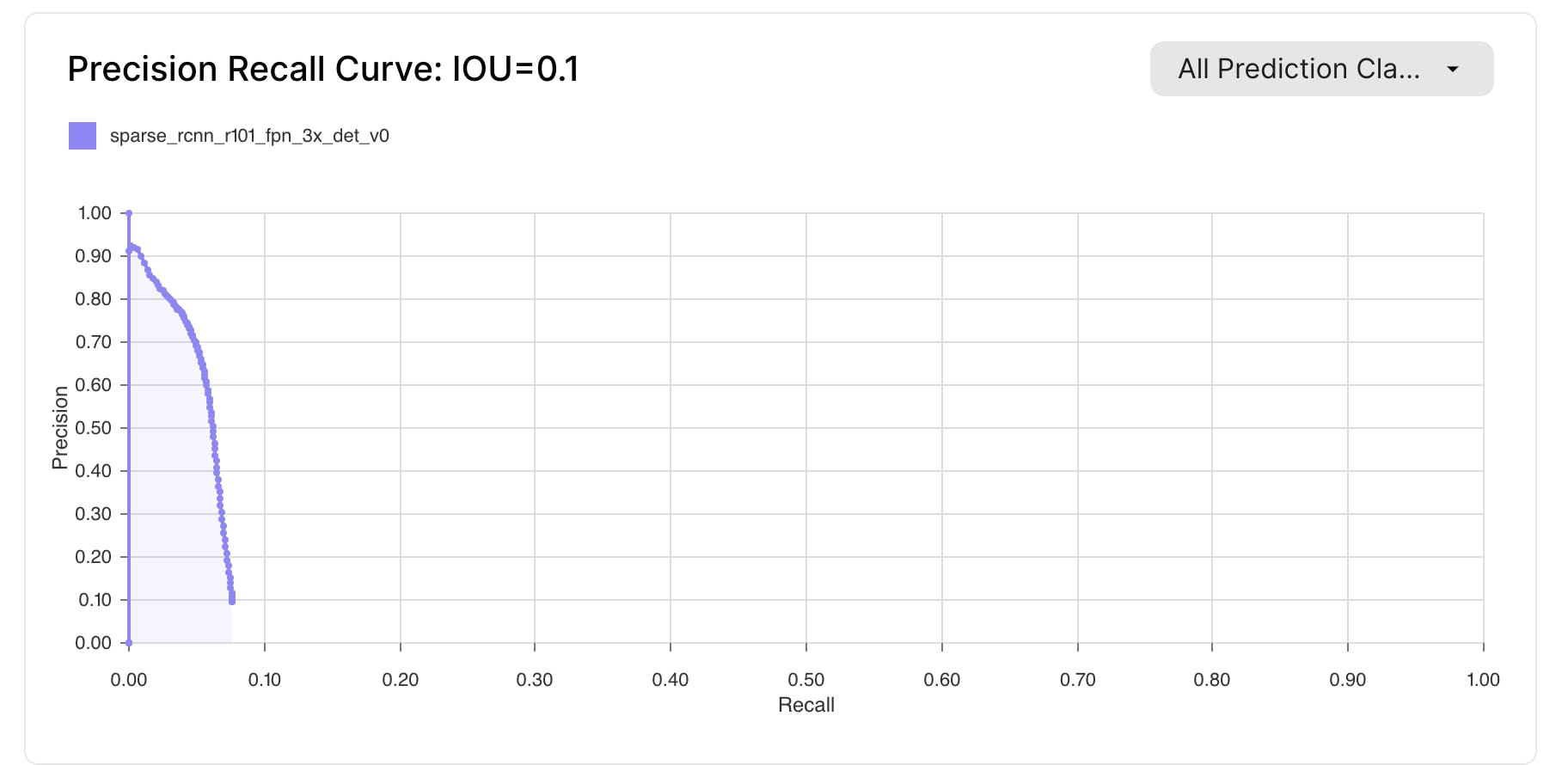
Intersection over Union (IoU) is an evaluation metric used in computer vision to confirm label quality. It measures the ratio of the area of overlap between the predicted label and the ground truth label to the area of their union. A ratio closer to 1 indicates a better-trained model.
Source: Scale AI
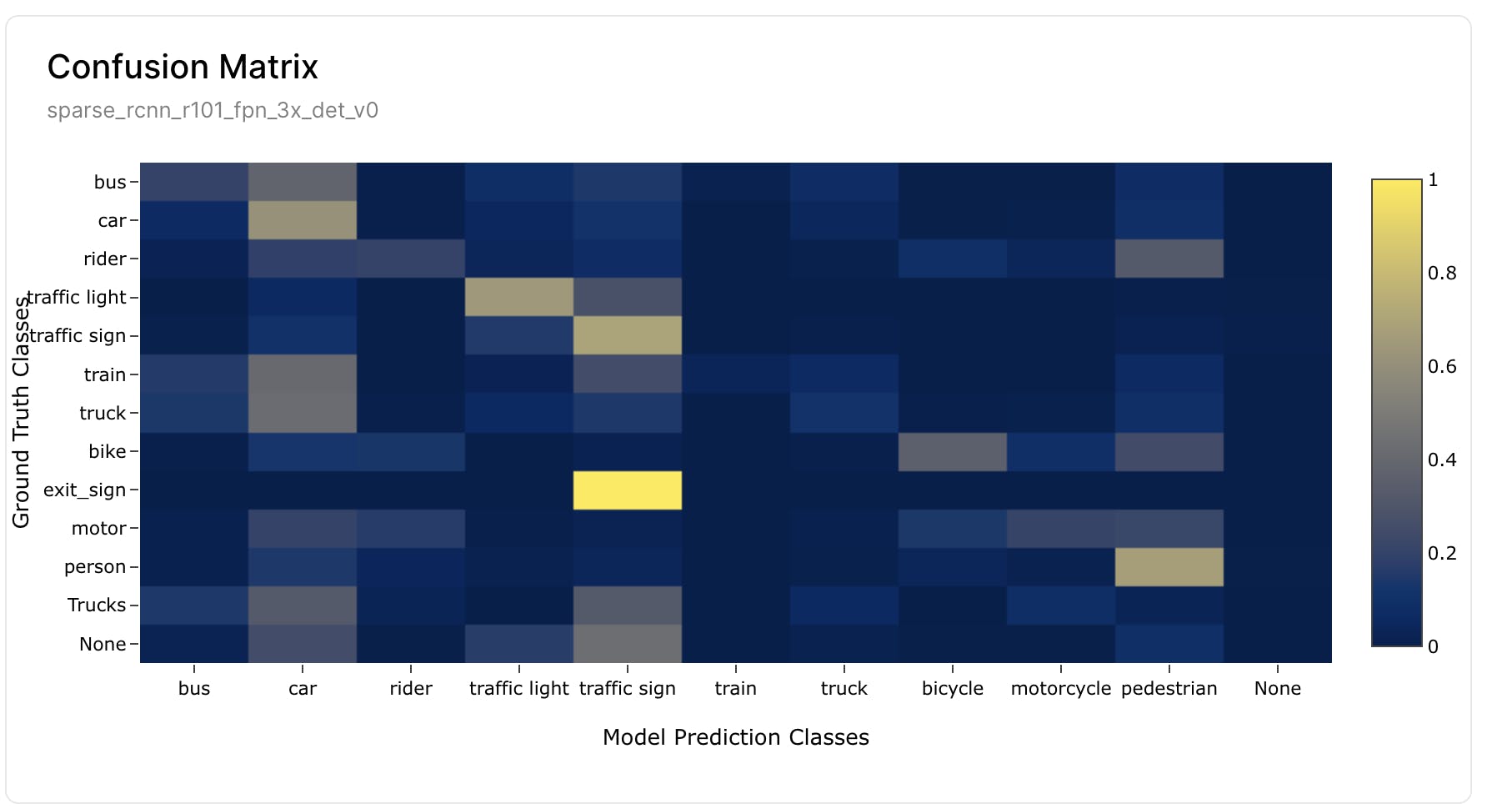
Confusion matrices are a powerful tool for understanding class confusion in models. They compare predicted and actual classifications, helping to identify misclassifications, such as predicting a traffic sign when the actual image is a train.
By combining confusion matrices with confidence scores, one can prioritize addressing misclassifications where the model is highly confident but incorrect. These confusions may be due to incorrect or missing labels or insufficient data for certain classes. For either of the two graphs, clicking on a piece of data will navigate a user to the filtered view of the image used to create that data point.
In the scenario tests view, a user is presented with the ability to regression test the models that they are using. Regression testing ensures that the quality of the model does not degrade over time, or with the addition of more dataset items. A Validate ScenarioTest is used to monitor model performance in key scenarios. It operates on a subset of data (Slice) and includes various evaluation metrics. Users can compare the model's performance against baseline models or evaluate if it meets specific thresholds, such as checking if the IoU of a model is greater than 0.8 on the selected data slice.
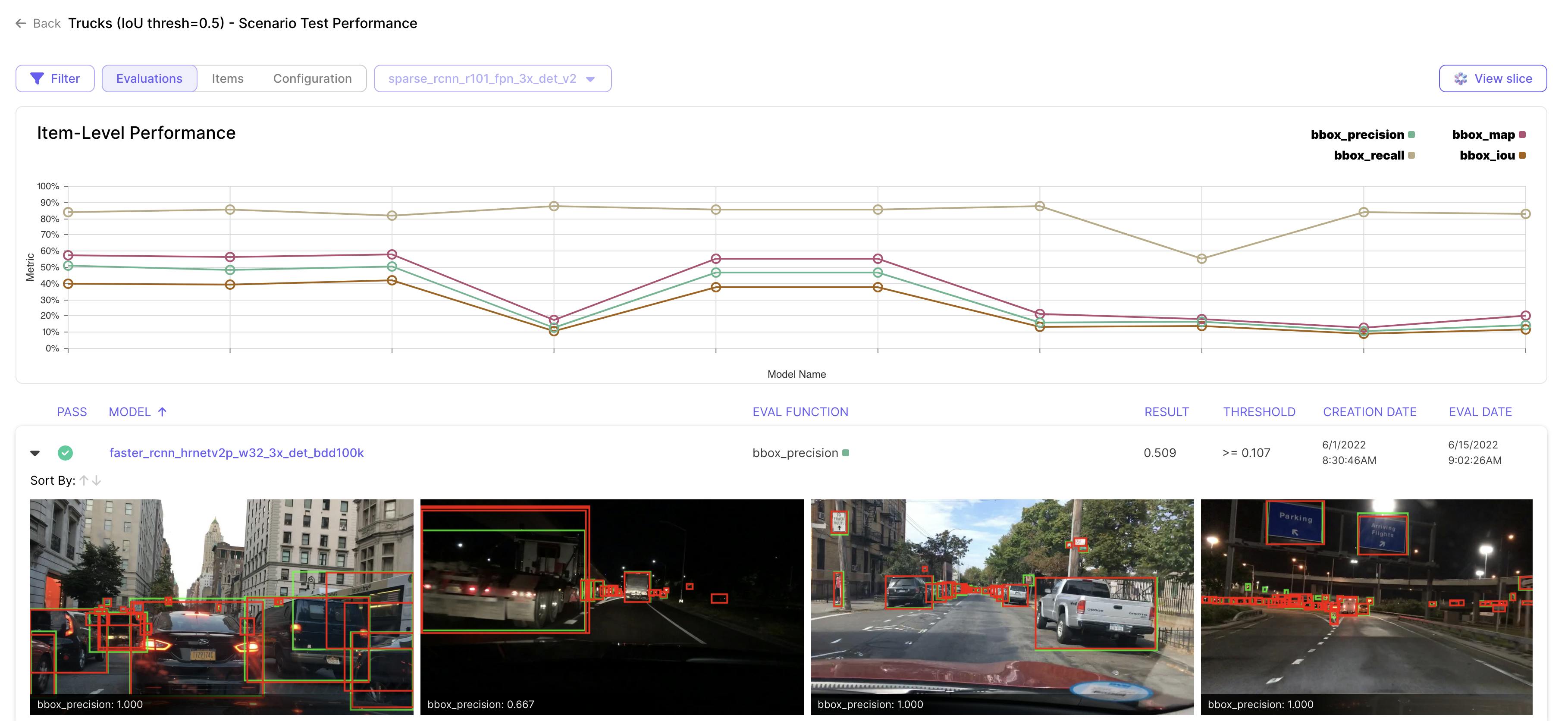
Source: Scale AI
The Item-Level Performance indicates different performances of each evaluation function, which can be specified by the user. The list under the graph indicates which model ran, which data was used, and the overall metrics of the run.
Jobs
Jobs are specific tasks that are running in the pipeline, and their progress is displayed in this view.
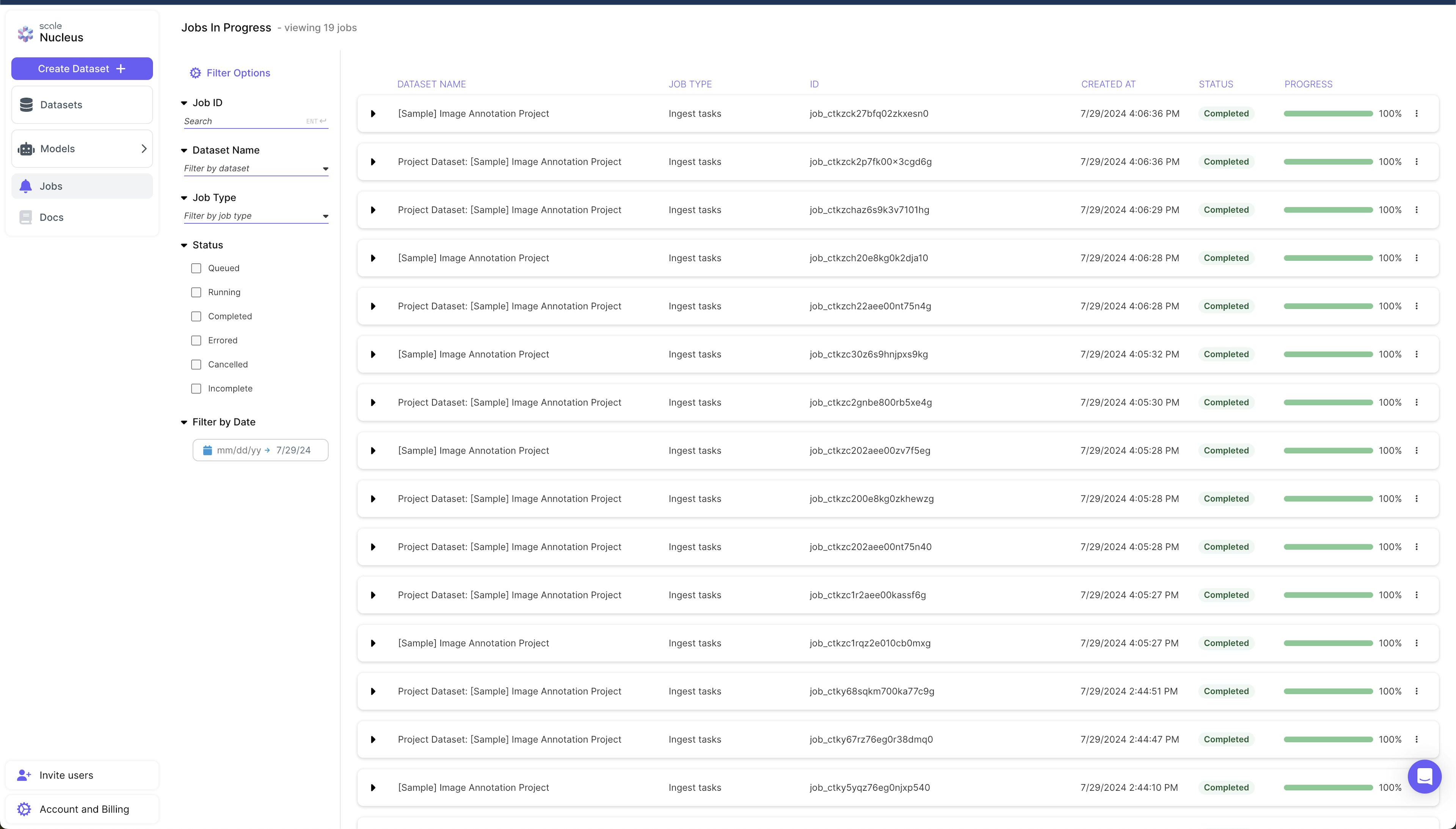
Source: Scale AI
Generative AI Platform
The Scale GenAI Platform is a solution designed to enhance the development, deployment, and optimization of Generative AI applications. It enables using advanced Retrieval Augmented Generation (RAG) pipelines to transform proprietary data into high-quality training datasets and embeddings, supporting the fine-tuning of large language models (LLMs) with both proprietary and expert data to improve performance and reduce latency.
Source: Scale AI
The platform includes a range of tools for evaluating and monitoring AI models, ensuring their reliability and accuracy. This includes the ability to compare base models, perform automated and human-in-the-loop benchmarking, and manage test cases with detailed evaluation metrics. These features enable pinpointing model weaknesses and improving accuracy.
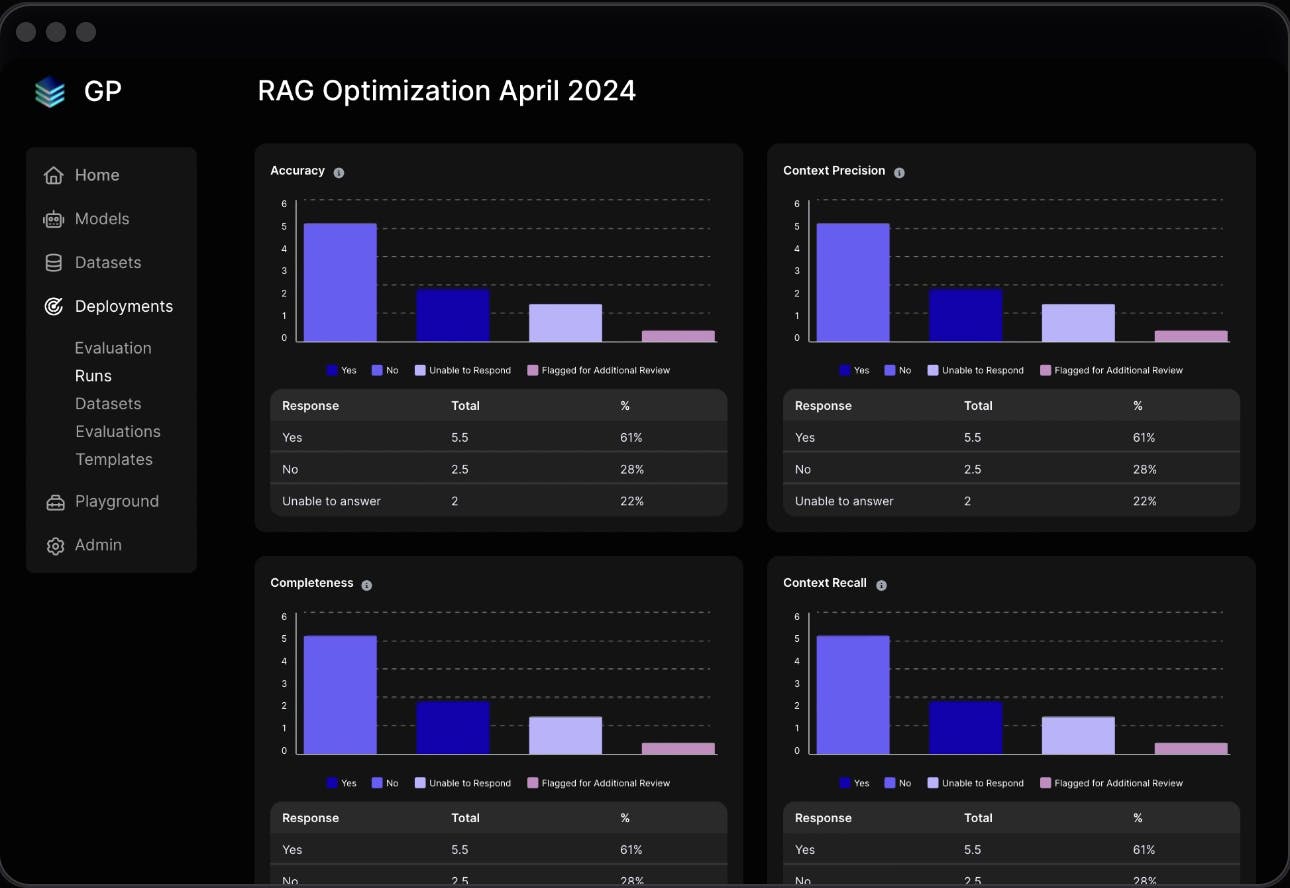
Source: Scale AI
Scale AI's infrastructure allows for the management and monitoring of custom models, with enterprise-grade safety and security built-in. Users can create new deployments, adjust settings, and monitor token consumption and API usage through convenient dashboards. The platform supports both commercial and open-source models.
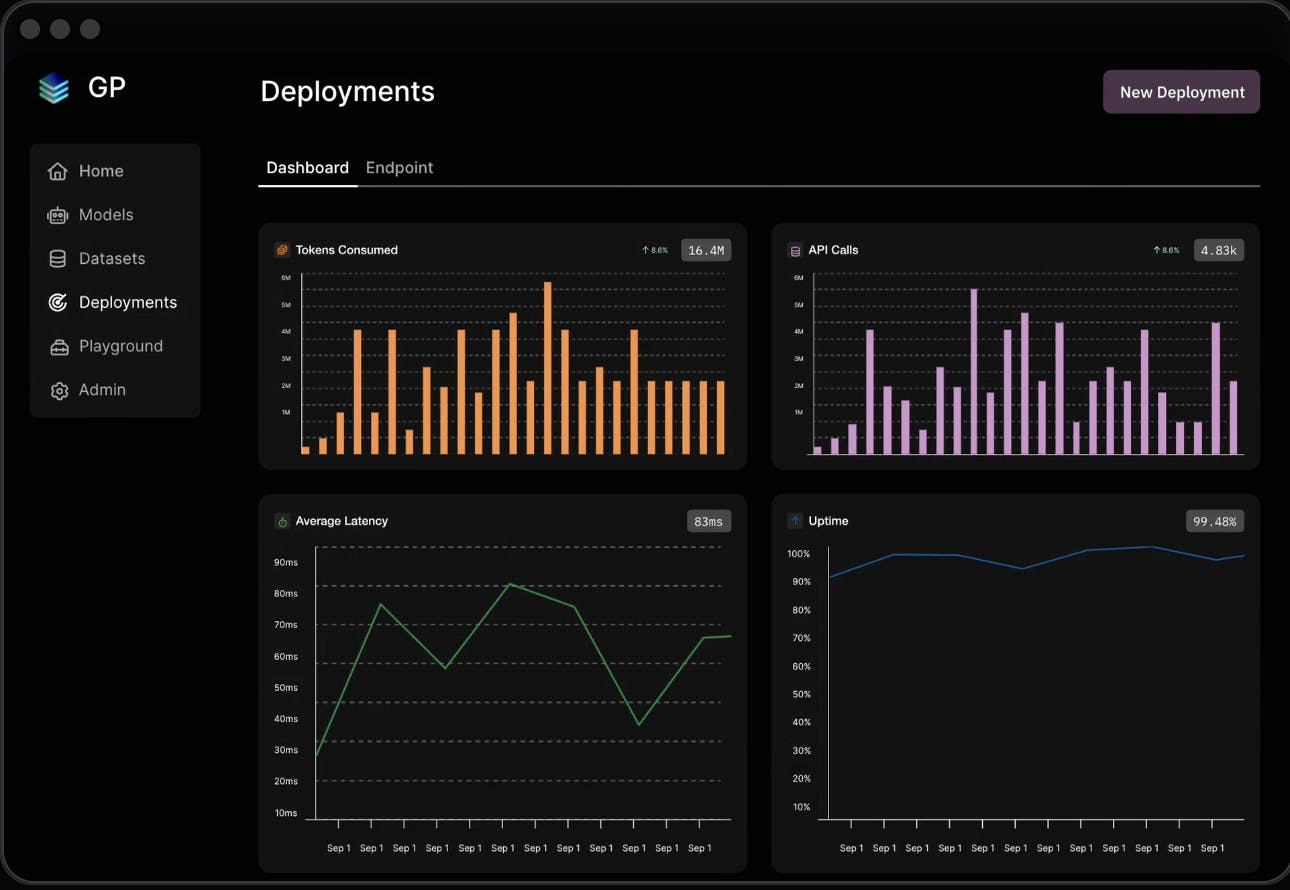
Source: Scale AI
The Scale GenAI Platform ensures data remains private and secure within virtual private clouds (VPCs) and supports rigorous testing to maintain the integrity of AI applications. By leveraging human-in-the-loop testing and extensive evaluation tools, the platform ensures that AI models are safe, responsible, and effective for various use cases, from employee productivity to customer support.
Source: Scale AI
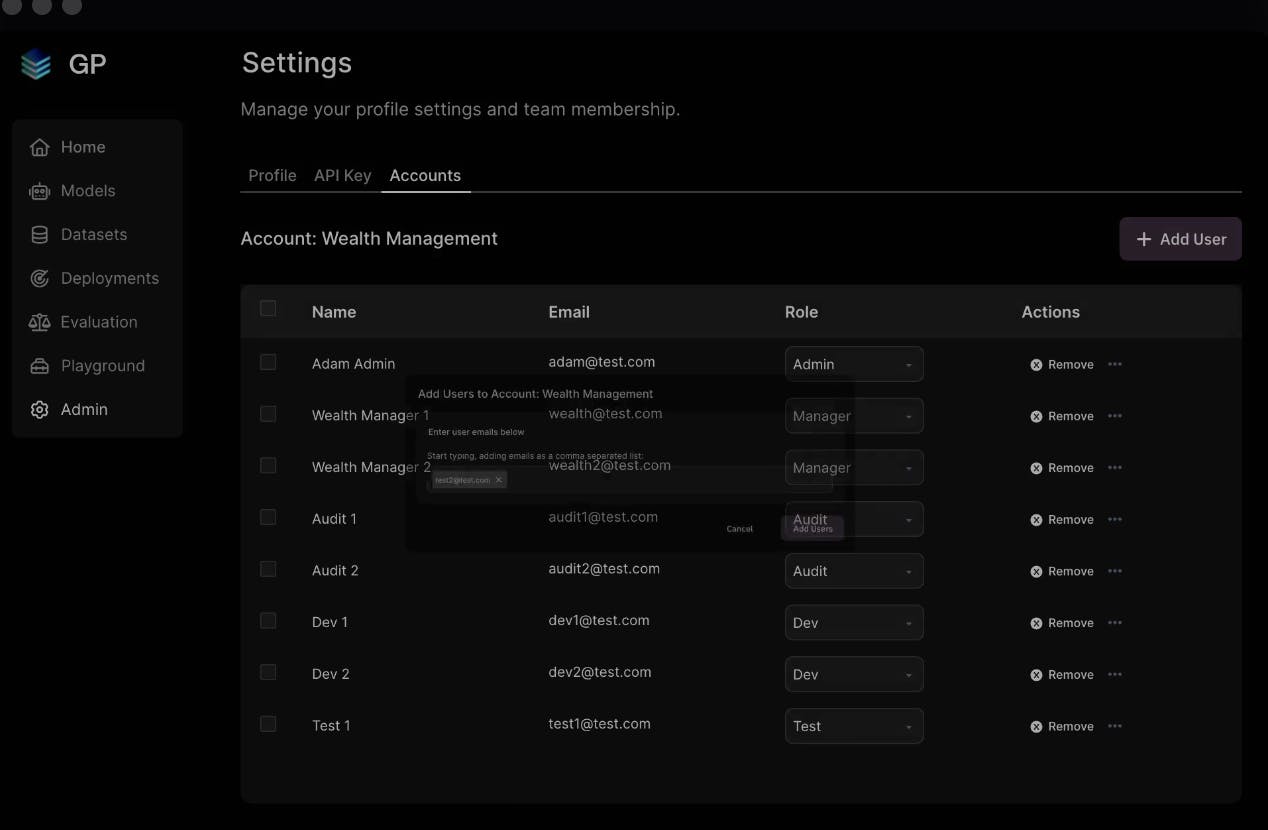
Scale Spellbook is Scale AI’s product designed for developers to build, compare, and deploy large language model apps. Spellbook was announced in November 2022. Its features include scaling CPU and GPU computing, managing model deployments and A/B testing, and monitoring real-time metrics such as uptime, latency, and performance. Spellbook also includes structured testing for ML models through regression tests and model comparisons.
A large language model (LLM) app consolidates prompts, models, and parameters for a specific use case, and users should create separate apps for each use. Examples include apps for converting text to SQL, generating marketing copy, summarizing tweets, and classifying products.
Source: Scale AI
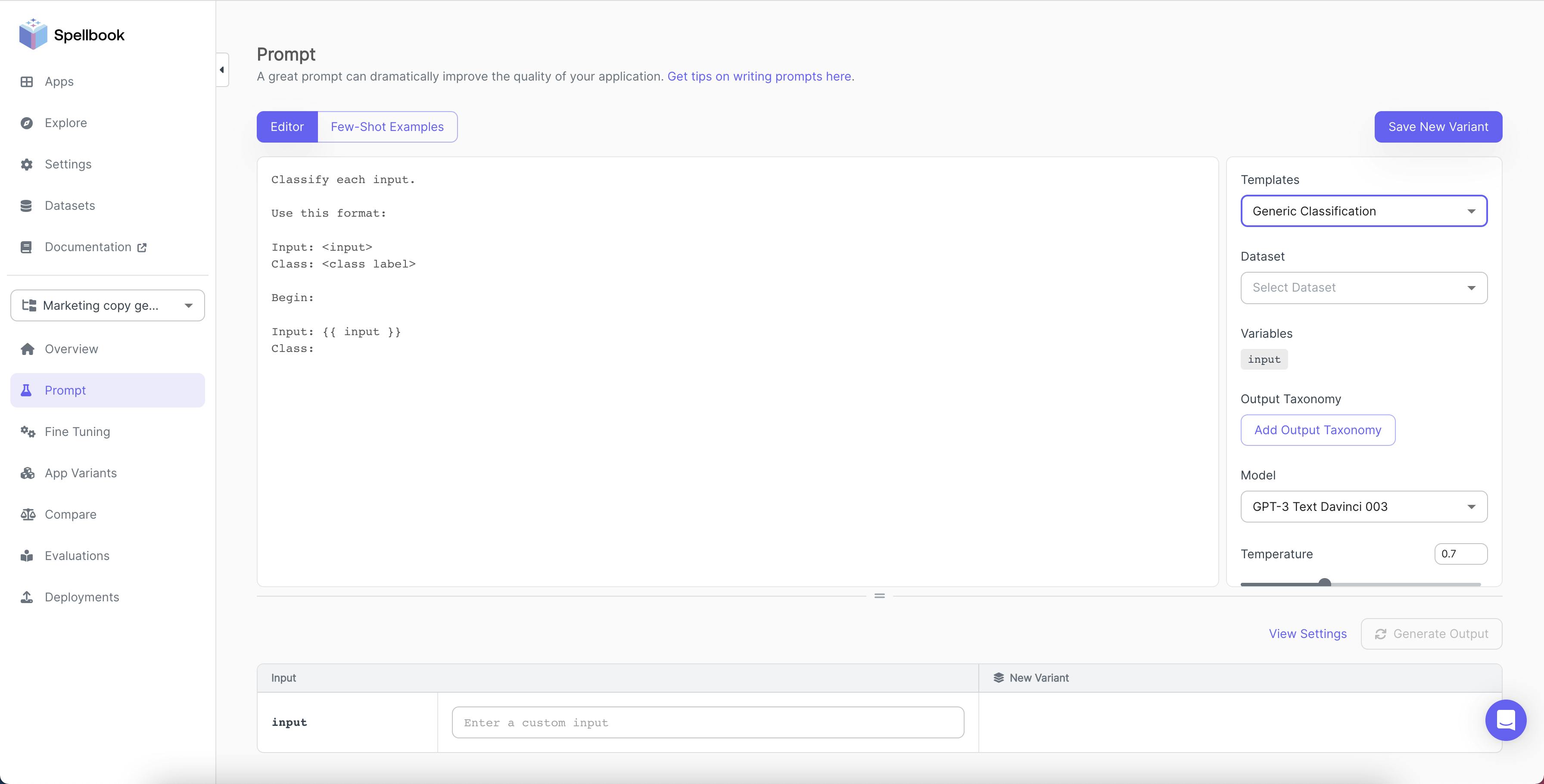
Prompt templates help users generate text by using structured prompts. These templates include pre-defined prompts with placeholders for specific information. Users can select a template and input the necessary details, enabling the model to create text based on that information.
Source: Scale AI
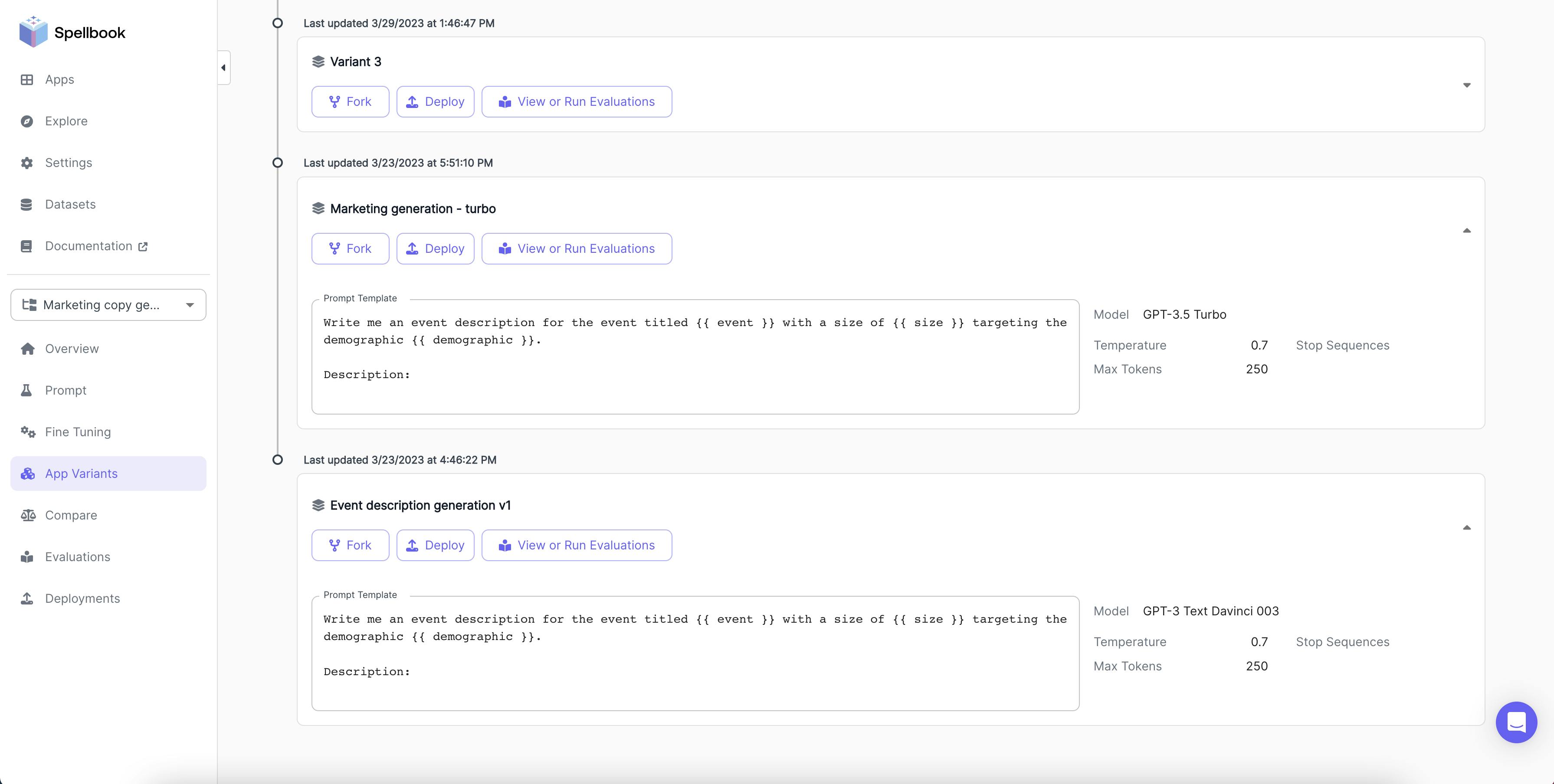
Different versions of the created app can be viewed on the App Variants page. They can also perform actions such as forking, which copies the variant's settings into a new variant; deploying, which creates a deployment from a variant; and viewing or running evaluations to assess the variant's performance through programmatic, human, or AI evaluation.
Source: Scale AI
While crafting a good prompt and providing context examples can enhance LLM performance, such prompts are not always sufficient or cost-effective. Fine-tuning the model on a larger set of task-specific examples offers some advantages: it eliminates the need for specific prompts, reduces token costs, improves inference latency by not requiring input examples, and allows the model to learn from examples. As of October 2025, Spellbook supports fine-tuning on OpenAI models and FLAN-T5.
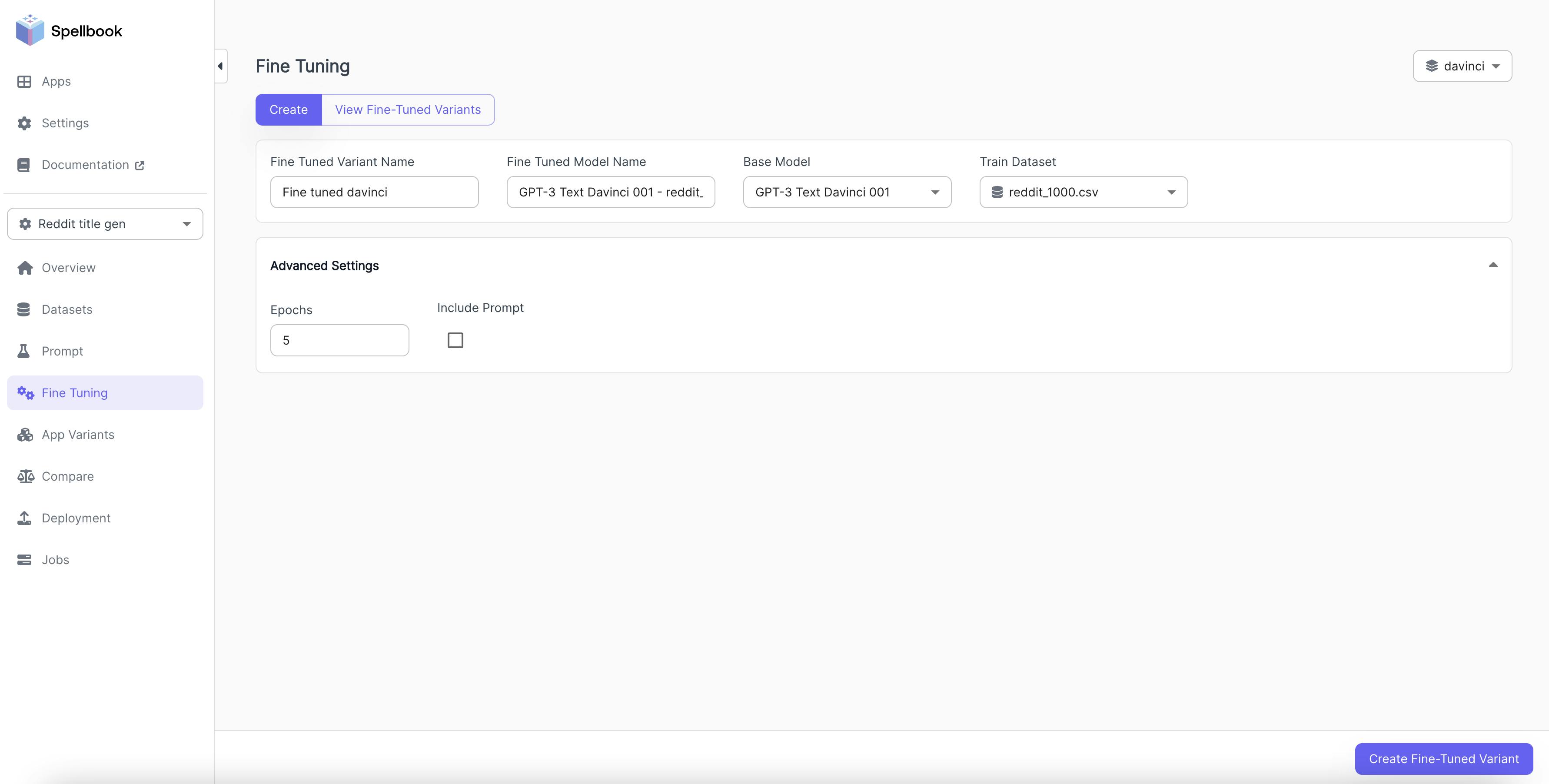
Source: Scale AI
For fine-tuning a model, two key parameters must be set: epochs and the learning rate modifier. Epochs determine how many times the model trains on the entire dataset. The learning rate modifier adjusts the sensitivity of the model to the training data.
Source: Scale AI
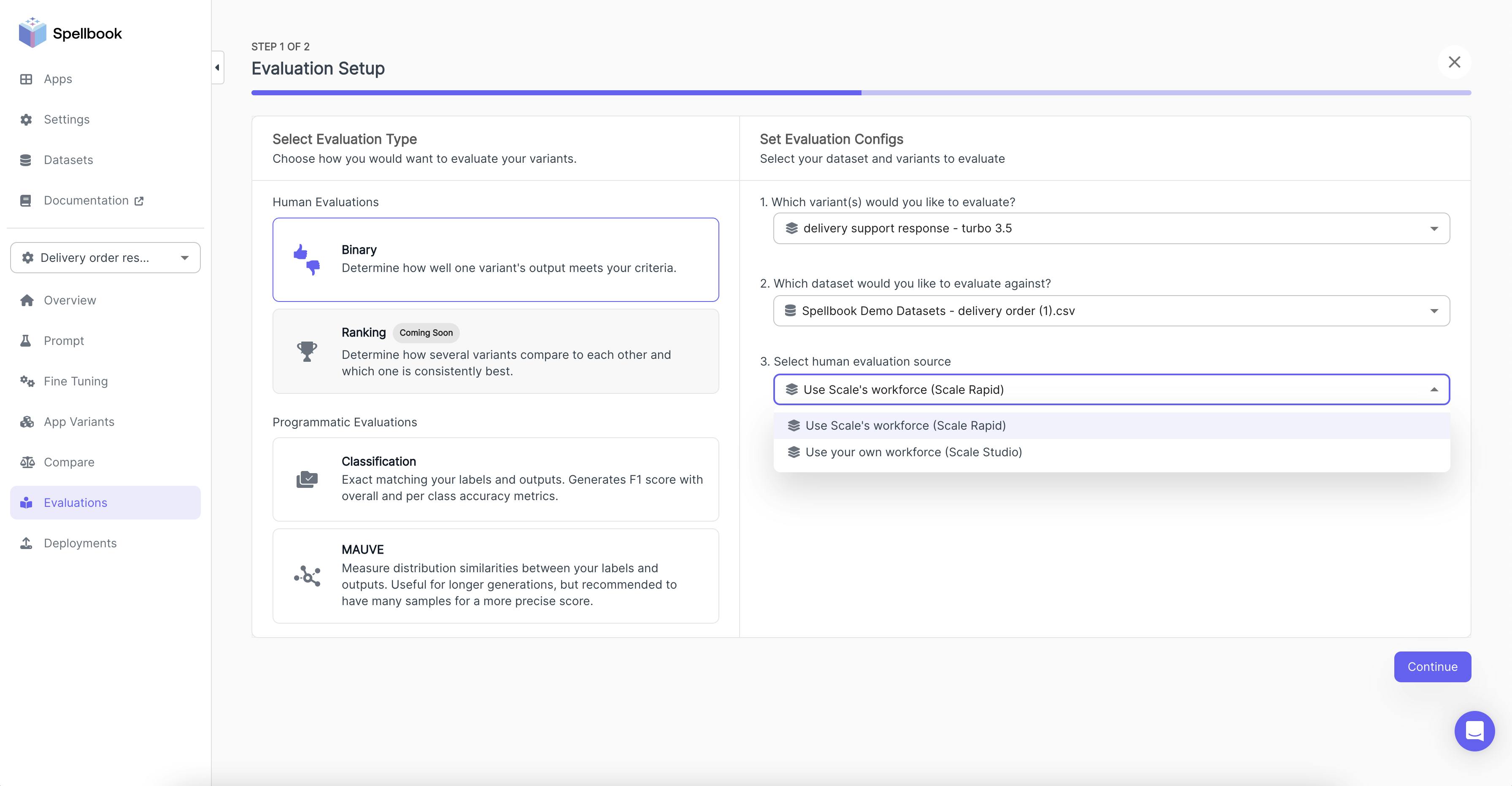
Evaluations in Spellbook provide quantitative metrics to determine the best model for specific use cases. Options include Human Evaluations and Programmatic Evaluations. For generative applications, users can employ Scale's human evaluation integrations. They can select a variant and a dataset, choosing between Scale's global workforce or their internal workforce. Users must define the task and evaluation criteria for the human evaluators.
Users may opt for programmatic evaluations for other use cases:
Classification: Compares ground truth with model outputs, generating F1 scores and accuracy metrics. The F1 score evaluates a model's predictive ability by examining performance in each class individually rather than overall accuracy by combining two metrics: precision and recall, providing a balance between the two to give a comprehensive assessment of the model's effectiveness.
Mauve: Measures distribution similarities for longer generations.
Scale Donovan

Source: Scale AI
Scale Donovan is an AI suite for the federal government. Donovan ingests data from cloud, hybrid, and on-premise sources, organizes data to make it interactive, and enables operators to ask questions to sensor feeds and map/model data. Further, Donovan produces a course of action, summary report, and other actionable insights to help operators achieve mission objectives.
Information Retrieval
Source: Scale AI
Donovan integrates Retrieval-Augmented Generation (RAG), allowing users to use Large Language Models to interact with mission-related information. Donovan has a chat interface that can extract information from documents and translate them using natural language semantics, using a model selected from those supported.
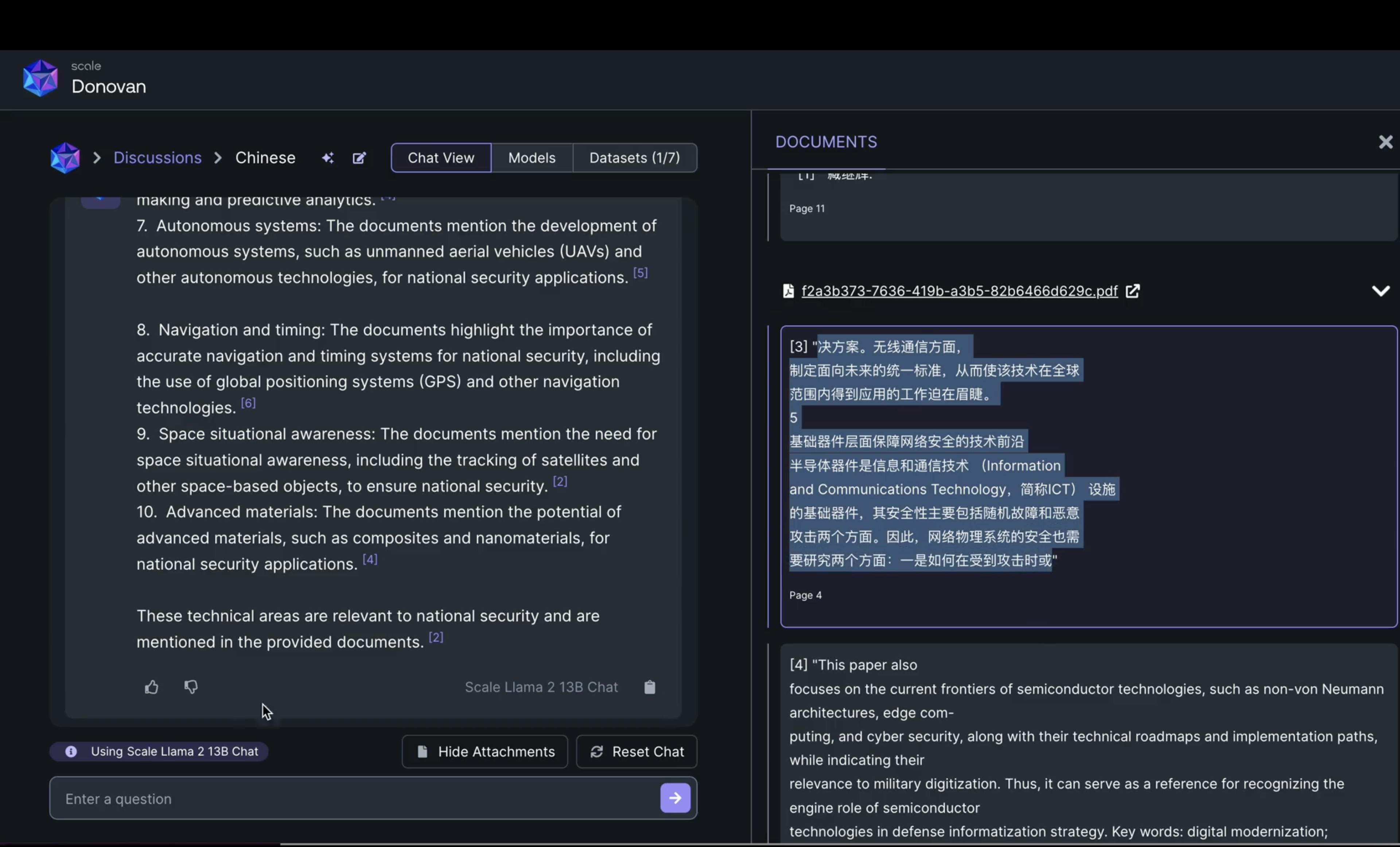
Source: Scale AI
Geospatial Chat
Donovan features geospatial chat, combining geographic filtering with LLM capabilities. Users can interact with a map, select specific areas, and pose location-based questions.
Source: Scale AI
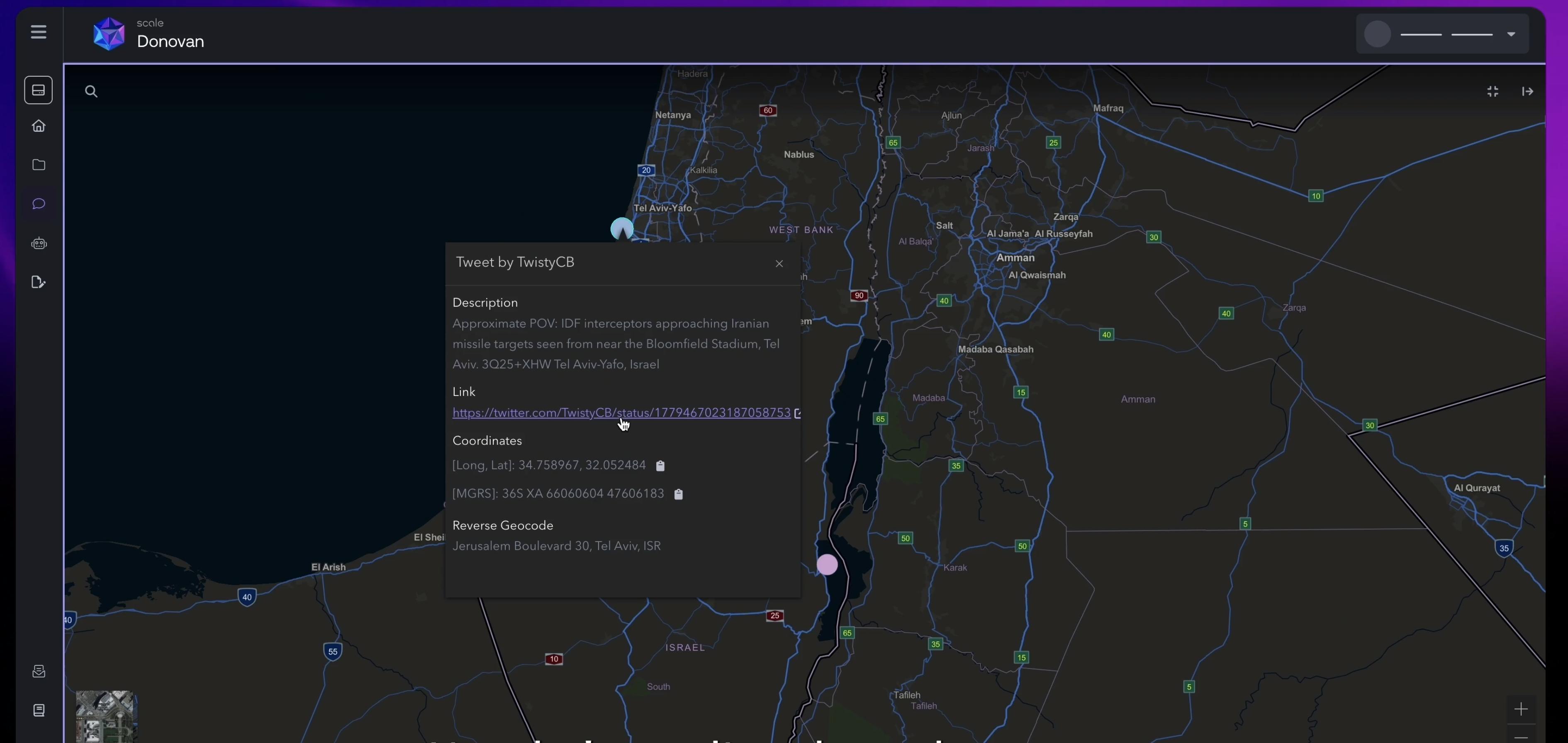
Donovan provides responses relevant to the chosen area and pins locations on the map with enriched metadata from citations.
Source: Scale AI
Text-to-API
Donovan's text-to-API feature enabled natural language queries to be translated into API requests, facilitating integration with other applications or systems. This allows Donovan to fetch and relay information from connected systems in natural language, streamlining interactions with complex databases and enhancing productivity and decision-making through partnerships with Flashpoint, Strider, and 4DV.
Report Generation
Users can also generate reports using LLMs, incorporating new data as it becomes available. This feature significantly reduces manual effort, allowing users to focus on strategic tasks and cutting workflow times from hours to minutes.
Source: Scale AI
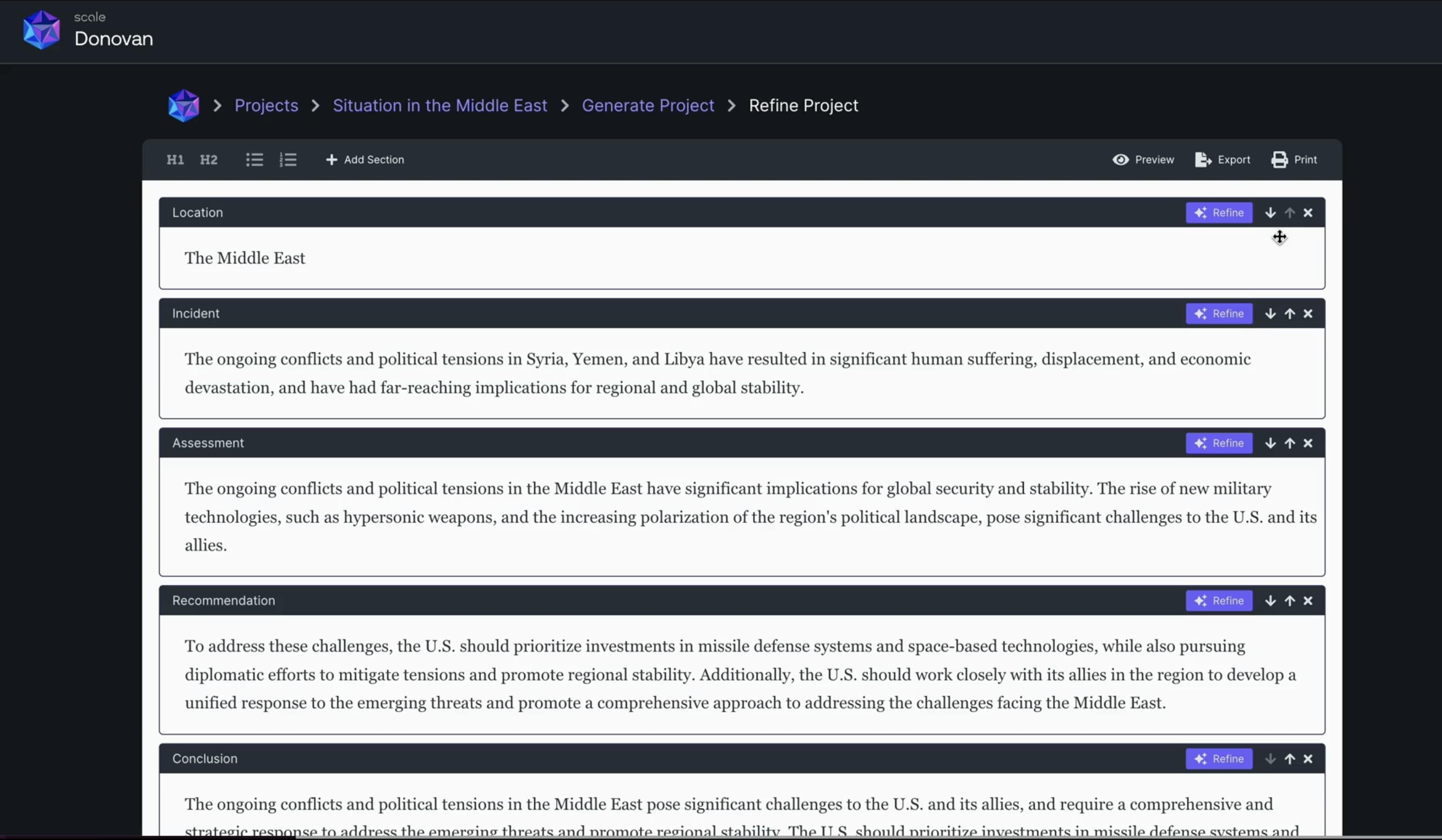
Donovan supports customized report generation through templates designed for common information requests or specific operational documents. Once the report’s general information is added, models that can be chosen will operate and act upon the given information to generate a template report or project that the users can then refine.
Source: Scale AI
Scale Evaluation
The state of AI evaluations limits progress due to several key challenges. One of the main issues is the shortage of high-quality, trustworthy datasets that haven't been overfit, resulting in less reliable evaluation outcomes. Additionally, the lack of effective tools to help analyze and iterate on these results further hampers the ability to improve models. This comes alongside inconsistencies in model comparisons and unreliable reporting, making it difficult to draw meaningful insights. Together, these challenges are creating a bottleneck that restricts advancements in AI development.
According to the company, Scale Evaluation is built to help model developers gain insights into their models, offering detailed analyses of LLM performance and safety across various metrics to support continuous improvement.
Scale Evaluation identifies several key risks associated with LLMs, including the spread of misinformation, where false or misleading information is produced, and unqualified advice on sensitive topics like medical or legal issues that can cause harm. It also highlights concerns about bias, where harmful stereotypes are reinforced, and privacy risks involving the disclosure of personal data. Additionally, Scale Evaluation looks to combat how LLMs can be exploited for cyberattacks and may aid in the acquisition or creation of dangerous substances like bioweapons.
Scale AI has established a reputable evaluation platform by implementing several strategic measures, and was selected by the White House to conduct public assessments of AI models from leading developers. Scale AI’s research division SEAL (Safety, Evaluations, and Analysis Lab), supports model-assisted research, enhancing the platform's evaluation capabilities. The company has trained thousands of red team members in advanced tactics and in-house prompt engineering, facilitating high-quality vulnerability testing.
Source: Scale AI
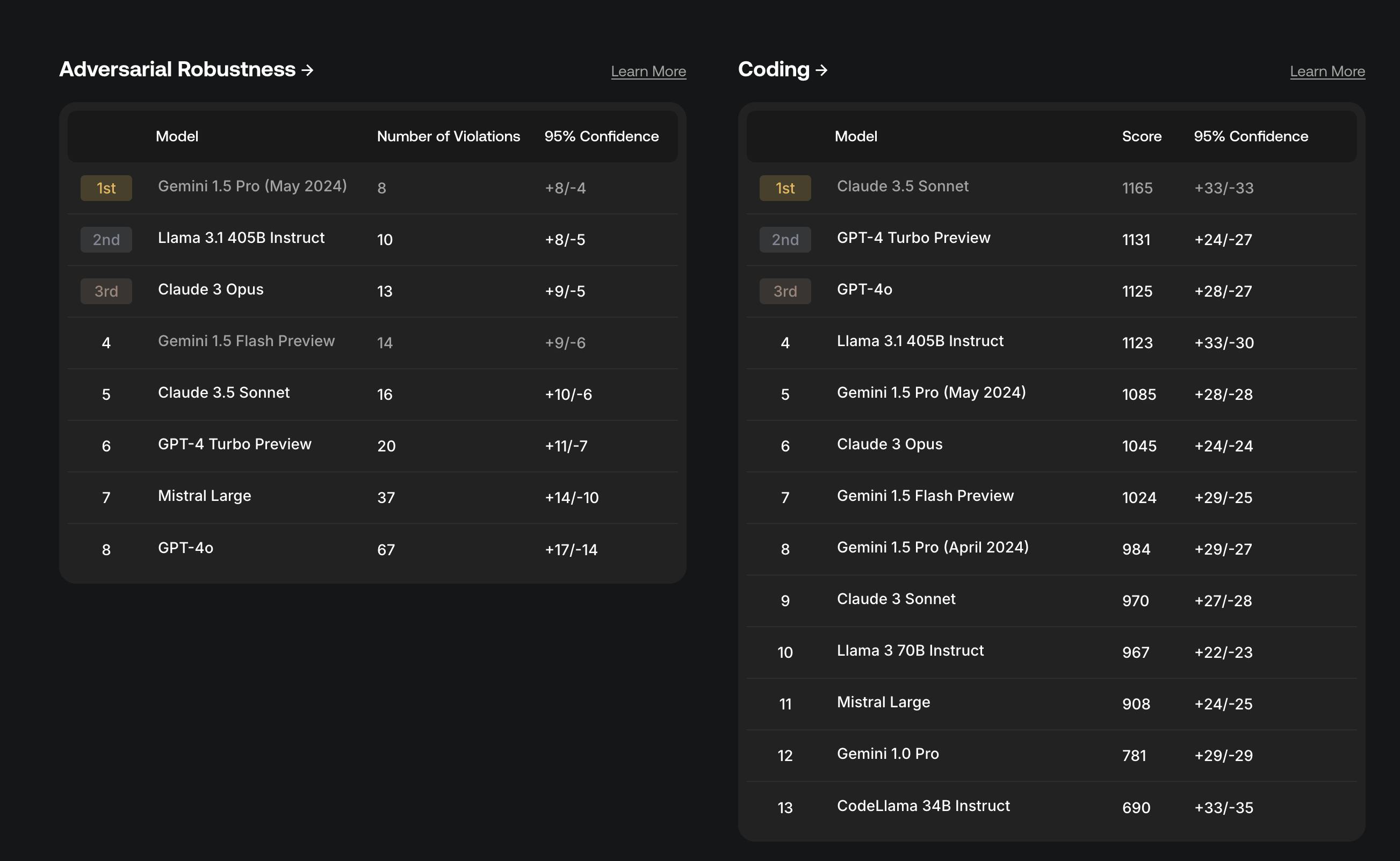
In May 2024, Scale AI introduced the SEAL Leaderboards, a ranking system for LLMs developed by its Safety, Evaluations, and Alignment Lab (SEAL). These leaderboards provide an unbiased comparison of frontier LLMs using curated, private datasets, ensuring that rankings accurately reflect model performance and safety. By covering domains such as coding, instruction following, math, and foreign languages, the SEAL Leaderboards offer a comprehensive evaluation process.
Unlike most public benchmarks, Scale's leaderboards maintain integrity through private datasets and limited access to prevent gaming or overfitting. The platform also emphasizes transparency in its evaluation methods, providing insights beyond just rankings. Scale’s goal is to drive better evaluations and promote responsible AI development by continually updating leaderboards, expanding coverage to new domains, and working with trusted third-party organizations to ensure the quality and rigor of assessments.
Scale AI frequently experiments with new products to determine market viability, which has contributed to the partial launch or discontinuation of offerings like Synthetic, Document AI, Ecommerce AI, and Chat. This iterative approach allows Scale AI to identify and focus on products that gain traction and meet customer needs.
Market
Customer

Source: Scale AI
As of October 2025, Scale AI defines its customer base as falling into three segments: generative AI model companies, US government, and enterprise. Scale AI’s generative AI model customers include OpenAI, Nvidia, Cohere, and Adept.
In the enterprise segment, the customer base is split by general industries. For example, in the automotive space Scale AI supports General Motors’ Cruise, Zoox, Nuro, and other autonomous driving companies that require labeled camera data. Scale AI’s robotics customers include Kodiak Trucks, Embark, Skydio, and Toyota Research Institute.
Under the government segment, Scale AI serves the federal government and defense contractors. Key customers include the US Army, the US Air Force, and the Defense Innovation Unit.
Market Size
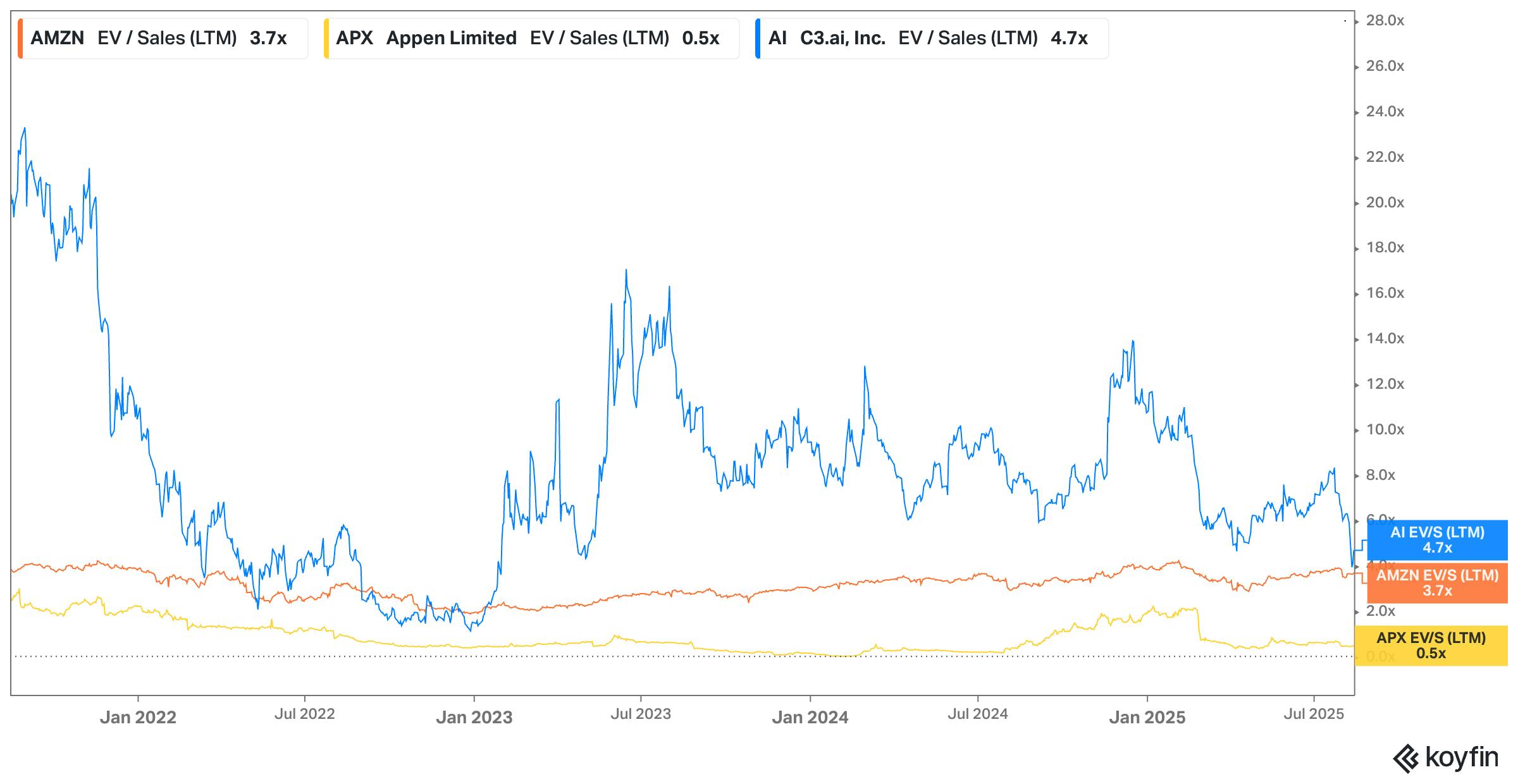
Scale AI’s primary service is data annotation. The data collection and labeling market was estimated at $4.9 billion in 2025, is expected to reach $13.8 billion by 2030 at a CAGR of 23% over the period.
Source: Koyfin
Competition
Within the data collection and labeling market, Scale AI faces competition from players such as Amazon Mechanical Turk, Labelbox, Appen, and Hive. These competitors also utilize humans to label data for companies that don't have the resources to do it themselves. Given the commoditized nature of the data labeling industry, companies find it challenging to establish unique competitive advantages beyond operational efficiency.
Scale AI’s competitive advantage in the long term comes from improving its in-house ML labeling algorithms to eliminate the need for manual human labeling. As Scale AI expands its operations into different domains, the diversity of the datasets plays a crucial role in training the ML models, and gives Scale AI a significant edge in terms of data quality and variety. In a 2021 overview of Scale AI’s business, Packy McCormick explained:
“Scale would agree that a human-heavy approach isn’t the right one in the long-term, but it’s crucial to the data flywheel. As Scale’s human teams label data, they’re also training Scale’s labeling models. Over time, the ratio of human-to-machine has decreased; more work is being done by the algorithms. The move to more algorithmic tagging is actually a boon for Scale, which has trained its models on more human labels than nearly anyone in the world. It’s much worse for competitors like Appen, which are more akin to Upwork-for-labelers than an AI company.”
With the introduction of new products, Scale AI has evolved from a data collection and labeling company into a comprehensive ML infrastructure company. The more traditional players in this category are much less commoditized:
ML Companies: Companies like Databricks build ML products on top of a key differentiated wedge. For Databricks this wedge is its data lakehouse, which stores the data that its AI workflows and model training systems consume. Similar companies include C3, H2O, and Dataiku.
Enterprise Cloud Platforms: Companies like AWS have an ML ecosystem as part of their product line, including Mechanical Turk to label data, S3 and Redshift to store that data, and Sagemaker to train ML models. Microsoft and Google are building similar platforms on Azure and GCP.
Scale AI falls in the first category, attempting to build ML tools on top of its wedge of data labeling. However, since Scale AI doesn’t own storage itself, it relies on external storage solutions like AWS’s S3, which can make Scale AI's subsequent ML products more expensive compared to AWS.
Data Collection & Labeling Market
Labelbox: Founded in 2018, Labelbox is a training data platform for machine learning applications. As of October 2025, the company had raised a total of $189 million in funding from investors such as Andreessen Horowitz and Snowpoint Ventures. In January 2022, Labelbox raised a $110 million Series D led by Softbank at an undisclosed valuation. Like Scale AI, Labelbox offers a platform for training data for AI models but differs in its more exclusive focus on machine learning applications.
Hive: Founded in 2013, Hive offers cloud-based AI solutions for understanding content, similar to Scale AI. As of October 2025, Hive has raised a total of $121 million from investors including General Catalyst and 8VC. In April 2021, the company raised a $50 million Series D at a $2 billion valuation. While Scale AI has an emphasis on government and enterprise cloud services as its customer base, Hive promotes prebuilt models for marketplaces, dating apps, and other B2C and peer-to-peer oriented companies. As a result, Hive focuses more on real-time content tagging for moderating user-generated content. Scale AI’s government and enterprise focus likely makes its product more useful for companies developing complex AI/ML services.
Appen: Founded in 2011, Appen collects and labels content to build and improve AI models. In January 2017, Appen was listed on the Australian Securities Exchange. As of October 2025, Appen was trading at a market capitalization of $140 million. Like Scale AI, Appen focuses on enterprise AI solutions including extracting information from paperwork, object detection for autonomous vehicles, and other various data types. Appen holds partnerships with AWS, Nvidia, and Salesforce. Both Scale AI and Appen have landed long-term enterprise contracts. Appen focuses on humans-in-the-loop labelling, while Scale AI aims to automate labelling using proprietary algorithms.
V7 Darwin: Founded in 2018, V7 Darwin helps collect and label image and video content to improve computer vision models. As of October 2025, V7 Darwin had raised $43 million, with a $33 million Series A raise in November 2022. Scale AI focuses on large-scale, enterprise-level data labeling with a mix of human and automated efforts for high accuracy, while V7 Darwin focuses on computer vision projects for smaller teams and individual data scientists.
ML SaaS Market
Databricks: Founded in 2013, Databricks helps companies build ML products and has a custom data storage solution that its AI workflows and model training systems consume. In January 2025, Databricks raised a funding round, following a $10 billion Series J at a $62 billion valuation in December 2024. As of October 2025, the company had raised a total of $21.8 billion in funding across 15 rounds. In comparison to Scale AI, Databricks' unique selling point is its data lakehouse infrastructure, which serves as the foundation for all its ML products, whereas Scale AI has a broader ML focus.
AWS Machine Learning Suite: AWS ML Suite is a suite of machine learning tools provided by AWS. It competes with Scale AI in providing around 28 machine learning services as of August 2025. It is part of a larger suite of cloud services provided by Amazon. Amazon introduced its ML initiatives in 2015. Based on Scale AI’s past partnerships, however, Scale AI can be used alongside AWS or even integrate with it.
C3 AI: Founded in 2009, C3 AI helps companies build custom enterprise AI applications. Its flagship product offers the development, deployment, and operation of AI applications, driving efficiency and cost-effectiveness with a focus on enterprise data management. Scale AI provides customizable solutions tailored to specific needs. Its platform can be adapted to various industries and specific use cases, making it versatile for different AI projects.
Business Model
Scale AI does not publicly disclose its pricing model. It has two pricing tiers: one for enterprise clients, and one for individuals.
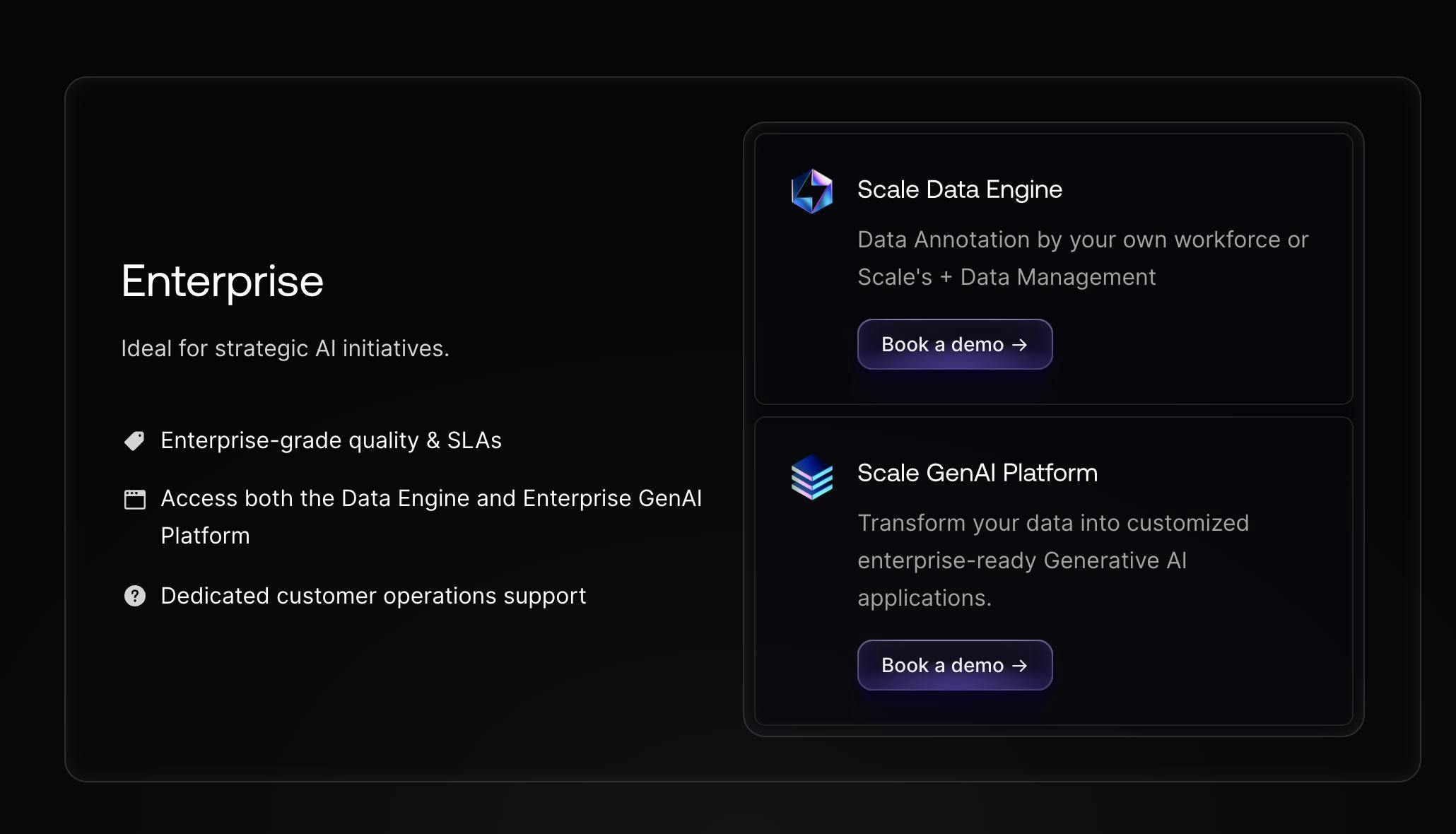
Enterprise
Source: Scale AI
Scale AI provides data annotation for enterprise customers on a custom pricing basis. Companies pay Scale AI to label data, with pricing dependent on the volume and the data type.
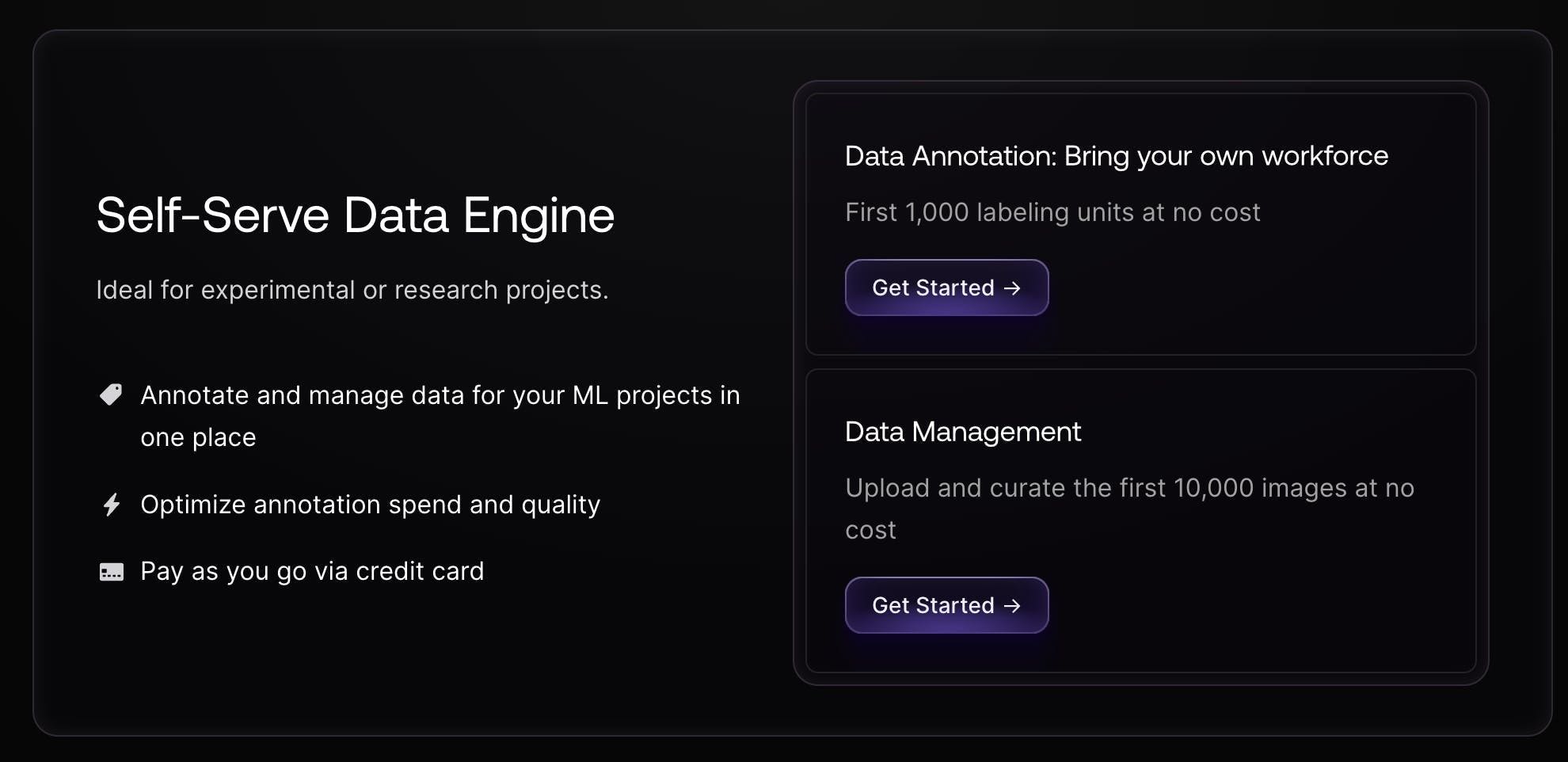
Self-Serve Data Engine
Source: Scale AI
For Scale AI’s self-serve data engine, a client can manage and annotate data for ML projects in one place, but use its own workforce. Scale AI prices this product on a pay-as-you-go basis. For annotations, the first 1K labeling units are free, while for data management the first 10K images are free.
The average gross margin of a software company is 75%; however, Scale’s gross margins are thought to be closer to 50-60% due to the heavy service component of the data labeling.
Traction
One unverified estimate indicated that Scale AI’s annualized run rate grew from $760 million in 2023 to $1.5 billion in 2024, up 97% YoY. This places it well within the pack of large AI startups. For reference, in 2024, OpenAI brought in $5.5 billion in ARR, while Anthropic brought in roughly $1 billion in ARR.
Scale AI has also experienced several rounds of layoffs. 14% of the workforce, equal to about 200 employees, was let go in July 2025 due to overhiring in the generative AI department. In January 2023, it laid off 20% of its workforce following excessive hiring in 2021 and 2022. As of October 2025, the company had 1000 employees.
Valuation
In June 2025, Scale AI received a $14.3 billion investment from Meta, at a valuation of over $29 billion. In return, Meta received a 49% stake in the company, but with no voting rights, and CEO Alexandr Wang joined Meta as Chief AI Officer.
In May 2024, Scale AI reported raising a $1 billion Series F round at a $13.8 billion valuation. The financing is a mix of primary and secondary, led by existing investor Accel with nearly all existing investors including YC, Nat Friedman, Index Ventures, Founders Fund, Coatue, Thrive Capital, Spark Capital, NVIDIA, Tiger Global Management, Greenoaks, and Wellington Management. This round also included new investors Cisco Investments, DFJ Growth, Intel Capital, ServiceNow Ventures, AMD Ventures, WCM, Amazon, Elad Gil, Meta, and Qualcomm Ventures. This follows a $325 million Series E round at a $7.3 billion valuation co-led by Dragoneer, Greenoaks Capital, and Tiger Global in April 2021.
Key Opportunities
Expansion to New Industries
Scale AI has focused on developing data labeling and annotation services for specific industries including autonomous driving. As of 2025, its customer base has expanded to include government agencies like the Department of Defense, marketplaces like Airbnb, fintech companies like Brex, and AI developer OpenAI. With the growth of new AI applications, Scale AI has the opportunity to diversify its customer base and leverage its existing data labelling capabilities in new markets.
Partnerships
Creating strategic partnerships with large organizations can significantly drive Scale AI's growth by providing access to extensive datasets, enhancing credibility, expanding market reach, and spurring innovation. For example, Scale AI's partnership with Toyota Research Institute has allowed it to access vast amounts of autonomous driving data, improving the accuracy and performance of its data labeling services.
Additionally, Scale AI’s collaboration with OpenAI has bolstered Scale AI’s reputation and expanded its product line to include LLM fine-tuning. Partnerships provide opportunities to build novel features and meet customer demands in the fast-moving AI industry.
Geographical Expansion
Scale AI generates most of its revenue from the US but has significant opportunities to expand into other regions. The European AI software market is projected to grow to $191 billion by 2026. By 2030, AI is anticipated to contribute $600 billion annually to the Chinese economy, with automotive, transportation, and logistics—areas where Scale AI specializes—expected to account for 64% of that growth.
Key Risks
Founder Departure
Alexandr Wang left his role as CEO of Scale AI in June 2025 to join Meta’s AI superintelligence lab. While he remains on the board, the absence of the company’s founder from day-to-day management creates significant uncertainty given that Wang has been viewed as the driving force behind Scale’s rapid ascent:
“The story of Scale AI is inextricably linked to the personal and ideological trajectory of its founder, Alexandr Wang. His unique background, prodigious talent, and evolving worldview have not only shaped the company’s strategic direction but have also been central to its successes and its most significant controversies.”
One month after Wang’s departure, Scale AI laid off 14% of its workforce, primarily targeting its generative AI team, which supported key clients like xAI and Google. This move may reflect internal turbulence and raises red flags for operational continuity and morale. Furthermore, relationships with clients and investors may be destabilized given that “Wang’s leaving Scale is clearly a blow to the company.”
Neutrality Concerns
In June 2025, Meta acquired a 49% stake in Scale AI, raising alarms about potential conflicts of interest. Major clients like Microsoft, OpenAI, and xAI began to withdraw or pause partnerships, citing risks that their proprietary data could inadvertently benefit Meta’s AI initiatives. Following Alexander Wang’s decision to join Meta, Scale AI’s largest customer Google announced that it was moving all key contracts off of Scale AI. Competitors reported a surge in demand, with Handshake seeing demand triple and Labelbox CEO claiming that his company will "probably generate hundreds of millions of new revenue” from Scale AI’s fleeing customers. The neutrality of Scale AI is under scrutiny, creating concern for its ability to retain existing customers as well as to secure new contracts.
Data Regulatory Exposure
One key risk to Scale AI is legislation in the EU, such as the General Data Protection Regulation (GDPR) and the AI Act, requiring data collected on its citizens to be stored in the EU and limiting certain types of AI applications. This legislation means Scale AI may not use data collected in the EU in other geographic areas, requiring it to build additional services to ensure compliance. Additionally, this may lead to fewer AI applications in the EU, and therefore, a smaller market for Scale AI.
Pricing Pressure in a Crowded Market
At the same time as competition is intensifying in Scale's core data labeling market, it faces more competitors in its expanded product stack, including Databricks, Labelbox Model, and Snorkel Flow. Scale's new products are entering a market dominated by established players and may not offer immediate bottom line benefits. Thus, it might be difficult for Scale AI to price features competitively. The crowded market may have led to major customers, including Samsung, Nvidia, and AirBnB, leaving Scale AI in January 2023.
Scale AI’s core differentiator is its lower cost of human-in-the-loop data labeling at scale. However, Scale AI may not have the same product moat as it expands to different parts of the ML infrastructure where stiff competition exists. As companies encounter financial challenges, the competitive focus may shift from features and efficiency to price, potentially reducing any margin expansion Scale AI gains from increased use of pre-labeling software.
Labor Practice Controversy
Scale AI has faced multiple class-action lawsuits, notably by contractors alleging misclassification (as independent contractors rather than employees), unpaid or withheld wages, and withholding overtime pay. Furthermore, several workers reported exposure to traumatic or disturbing content, such as assisting with self-harm AI responses, without sufficient emotional support. Since August 2024, the U.S. Department of Labor has been investigating Scale AI for potential violations of the Fair Labor Standards Act. If violations are confirmed, Scale AI could face significant penalties, profit margin reduction, and reputation damage.
Summary
Scale AI has established itself in the AI space as a data label provider that fuels enterprises, generative AI companies, and the government. Scale AI operates in the $4.9 billion data labeling market and posted 97% YoY ARR growth to $1.5 billion in 2024. Over time, the company has expanded into an AI infrastructure provider and has grown its product line. Its competitors include data labelling companies such as Appen, Labelbox, and V7 Darwin, as well as ML infrastructure companies like AWS, Databricks, and C3 AI. The company faces headwinds from regulatory constraints, pricing pressure in a crowded market, labor practice controversies, and significant neutrality concerns after Meta’s 49% stake prompted high-profile client departures. Scale AI’s future success will be determined by its ability to expand to new industries, form strategic partnerships with other corporations, and expand geographically.